






Nowy układ SoC od Nvidii będzie pierwszym 64-bitowym procesoremARM dla urządzeń z Androidem. Ten następca pokazanej w zeszłymroku 32-bitowej Tegry K1, która w benchmarkach wydajności grafikinie dała żadnych szans innym czipom SoC, tym razem ma zdeklasowaćkonkurencję także pod względem możliwości CPU. Znany jużprocesor graficzny ze 192 rdzeniami w architekurze Kepler zostałpołączony z dwurdzeniowym, 64-bitowym CPU „Denver”, zgodnym zarchitekturą ARMv8. Producent podkreśla,że nowy SoC jest całkowicie zgodny z 32-bitową Tegrą K1 podwzględem elektrycznym i mechanicznym, więc jego wdrożenie ma byćdla producentów sprzętu sprawą prostą.
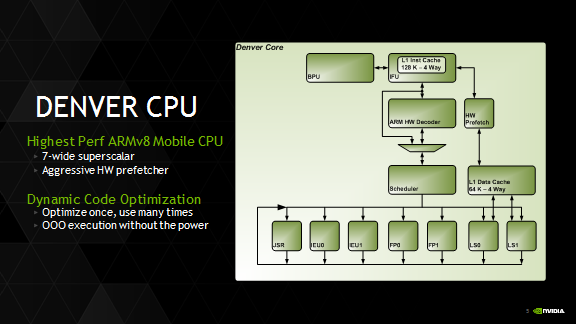

Dwa rdzenie w architekturze ARMv8, to w czasach gdy wieluproducentów ARM chwali się ośmiordzeniowymi CPU, wydawać sięmoże niewiele. Rdzeń jednak rdzeniowi nierówny, a kompatybilnośćz ARMv8 nie oznacza, że „Denver” jest po prostu kolejnym klonemmasowo produkowanych układów na licencji konsorcjum ARM. Każdy zrdzeni zbudowany jest w 7-stronnej superskalarnej architekturze (dosiedmiu mikrooperacji w cyklu zegara), ze 128 KB 4-drożnej pamięcipodręcznej L1 dla poleceń i 64 KB dla danych. Oba rdzeniewspółdzielą ze sobą 2 MB 16-drożnej pamięci podręcznej L2.
Te liczby jeszcze żadnej rewolucji nie zapowiadają, choć dużecache L1 (128 KB w porównaniu do 32 KB w typowych ARM-ach) możedawać do myślenia. Jak się jednak przyjrzeć architekturze nowegoprocesora, to widać, że NVIDIA zrezygnowała ze standardowejjednostki wykonawczej z wykonywaniem poza kolejnością (out-of-orderexecution, OoOE) jaką można znaleźć dziś w praktyczniewszystkich CPU, od czasów Pentium Pro. Popularność OoOE nie wzięłasię bez powodu. Pozwala ona na znacznie przyspieszenie działaniaprocesora, gdyż to sam procesor wybiera instrukcje, które majązostać wykonane w danym cyklu. Oczywiście logika implementującaten wybór nie jest za darmo – dodatkowe obwody zajmują miejsce izużywają energię tylko na to, by sterować optymalizacją.
W Denver mamy do czynienia tymczasem z klasyczną jednostkąwykonawczą typu in-order, wykonywaniem instrukcji w kolejności –z tym, że wykorzystującą dynamiczną optymalizację kodu.Uruchamiane na drugim rdzeniu oprogramowanie optymalizacyjne pozwalana przekształcenie najczęściej uruchamianych fragmentów kodu wwysoce stuningowane odpowiedniki w mikrokodzie. Trafiają one dodużego (128 MB) bufora, z którego są wywoływane w miarępotrzeby, bez konieczności ponownego dekodowania.
Zamiast więc stosować sprzęt do optymalizacji kodu, w Denveroptymalizacja odbywa się software'owo, szybko ograniczając kosztyprocesu wraz z wzrostem liczby wykonań danej jednostki.Przekształcenie kodu ARMv8 w wewnętrzny mikrokod pozwala na niemaldwukrotne zwiększenie wydajności procesora i znaczne zmniejszeniezużycia energii. W tych zaś sytuacjach, gdy kod niezbyt się nadajedo optymalizacji (niewiele jest wielokrotnie wykonywanychfragmentów), Denver po prostu bezpośrednio uruchamia instrukcjeARM, bez jego optymalizowania.
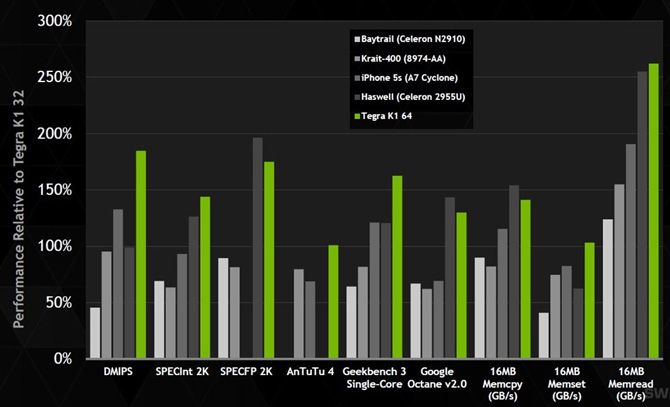
Taka dynamiczna optymalizacja działa ze wszystkimi aplikacjaminapisanymi na ARM, nie wymagając żadnych w nich zmian. Producenttwierdzi, że jego dwurdzeniowy procesor osiąga znacznie lepszewyniki zarówno dla jednowątkowych jak i wielowątkowych obciążeńroboczych, niż układy konkurencji, korzystające z czterech, anawet ośmiu rdzeni. W połączeniu z wysoką przepustowościąsuperskalarnej, 7-stronnej konstrukcji i bardzo dużej wydajnościenergetycznej, zapewnionej dzięki bramkowaniu obwodów, dynamicznejkontroli napięcia i częstotliwości zegara, Denver ma dorównywaćwielu popularnym układom x86, przy znacznie niższym zużyciuenergii.
Starsi Czytelnicy mogą pamiętać analogiczne rozwiązanie zprzeszłości, które niewątpliwie projektantów Nvidii musiałozainspirować w pracach nad systemem software'owej optymalizacji.Chodzi oczywiście o układyTransmeta, oszczędne energetycznie czipy x86, wykorzystującerdzeń typu VLIV, dla którego mikrokod przygotowywany był przezsoftware'owy optymalizator Code Morphing. Oczywiście nie oznacza to,że NVIDIA skopiowała pomysł Transmety – Denver pod względemarchitektury niczym nie przypomina tamtych czipów – ale widać, żeidea przyświecała ta sama: tam gdzie chodzi o oszczędzanieenergii, optymalizację lepiej przygotować na drodze software'owej.
Nie wiadomo jeszcze, czy NVIDIA będzie zainteresowanaprzystosowaniem swojej nowej, 64-bitowej Tegry K1 do Windows RT.Przeznaczony dla układów ARM system Microsoftu jest wciąż conajwyżej rynkową ciekawostką. Pojawiają się za to doniesienia,że 64-bitowa Tegra K1 będzie mogła trafić do chromebooków zwyższej półki. 32-bitową Tegrę K1 do swojego chromebooka wybrałniedawno Acer – i już pierwsze testy pokazują, że dzięki temuudało się połączyć bardzo długi czas pracy na baterii z bardzodobrą wydajnością, szczególnie w dziedzinie grafiki. Co będąfaktycznie potrafiły takie małe lekkie urządzenia z Tegrą K1Denver na pokładzie, powinniśmy zobaczyć jeszcze w tym roku.












