

Badanie jakości informacji i wiarygodności źródeł w Wikipedii
02.01.2021 | aktual.: 16.03.2021 19:13

Być może dla niektórych to będzie zaskakujące, ale w Wikipedii informacje nie muszą być prawdziwe, ważne aby zostały potwierdzone przez wiarygodne źródła. Ostatnia edycja Wikimedia Research Showcase 2020 roku była poświęcona problemowi dezinformacji i wiarygodności źródeł Wikipedii. Jest to comiesięczne publiczne wydarzenie prezentujące najnowsze prace zespołu badawczego Fundacji Wikimedia oraz zaproszonych prelegentów ze społeczności akademickiej. Miałem możliwość prezentacji najnowszych prac naukowych prowadzonych wspólnie z pracownikami naszej katedry. W tym artykule postaram się pokrótce opisać najnowsze badania naszego zespołu w zakresie oceny jakości informacji i wiarygodności źródeł w wielojęzycznej Wikipedii. Ponadto zastały krótko opisane dostępne narzędzia oceny jakości i wiarygodności oparte na badaniach naukowych.
Grudniowa edycja Wikimedia Research Showcase jest dostępna na YouTube, a slajdy z prezentacji są publikowane na SlideShare i figshare.
Wielojęzyczna Wikipedia
Według Ethnologue ludzie na świecie mówią ponad 7 tysiącami języków, z czego prawie 3 tysiące jest zagrożonych. Dla porównania, artykuły w Wikipedii są dostępne w 314 językach.

Ponad połowa światowej populacji mówi tylko 23 językami. Najpopularniejszym jest angielski, którym posługuje się około 1,27 miliarda ludzi. Jednak dla ponad 70% z nich język angielski nie jest ojczysty.
W swojej pracy doktorskiej, którą obroniłem w marcu 2019 r., opisałem metodę porównywania i wzbogacania informacji w wielojęzycznych serwisach wiki na podstawie analizy ich jakości. Jako przykład przyjęto najpopularniejszą witrynę wiki - Wikipedię. W celu weryfikacji proponowanej metody, w pracy zostały wykorzystane dane z 5 wersji językowych Wikipedii - angielski, białoruski, polski, rosyjski, ukraiński.

Znajomość tych języków oraz wyniki badań pozwoliły dojść do wniosku, że algorytmy zaproponowane w rozprawie można zastosować w innych wersjach językowych tej wolnej encyklopedii (jak również w innych witrynach wiki).
Wikipedię można edytować w każdym języku niezależnie, co prowadzi do takich problemów, jak:
- ten sam obiekt (miasto, osoba, wydarzenie itp.) można opisać na różne sposoby,
- użytkownik zwykle musi rozumieć te języki, aby sprawdzić/porównać informacje.
Dodatkowo ocena jakości informacji jest subiektywna i zależy od wersji językowej Wikipedii:
- każda edycja językowe określa własne zasady i standardy,
- standardy mogą się zmieniać w czasie.
Jednym z ważnych kryteriów jakości informacji w Wikipedii jest obecność wiarygodnych źródeł. Jednak ocena tego samego źródła zależy od wersji językowej Wikipedii. Dodatkową kwestią jest to, że wiarygodność tego samego źródła może się zmieniać w czasie.
Ocena jakości informacji w Wikipedii
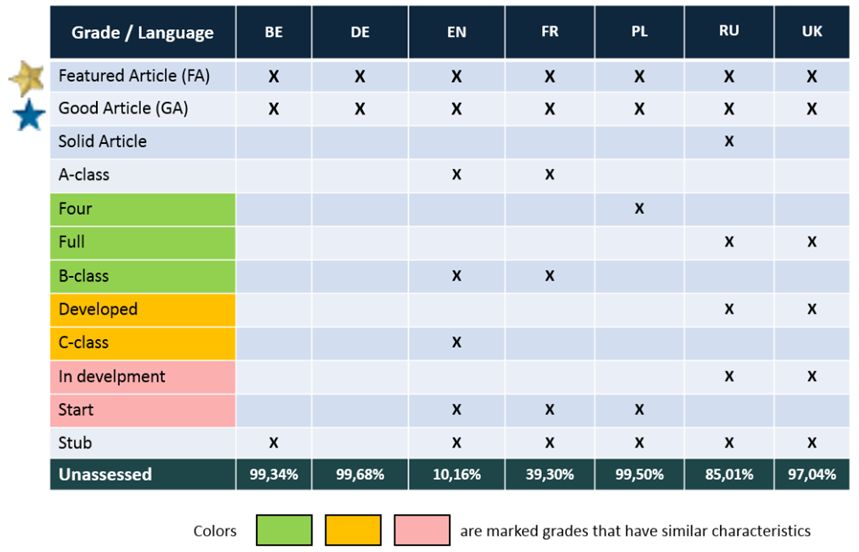
Każda wersja językowa Wikipedii może zdefiniować własny system oceny jakości artykułów. Często każda wersja językowa ma specjalne wyróżnienie dla artykułów, które są uważane za najlepsze - „Artykuły na Medal”. Jest też odznaka dla artykułów dobrej jakości, które jednak nie spełniają wszystkich kryteriów najlepszych artykułów - odznaczane są jako „Dobre Artykuły”.
Niektóre wersje językowe Wikipedii mają również inne oceny jakości, które mogą odzwierciedlać „dojrzałość” artykułu. W angielskiej Wikipedii oprócz najwyższych ocen „FA” i „GA” są też „A‑class”, „B‑class”, „C‑class”, „Start” i „Stub”. W rosyjskiej Wikipedii, oprócz dwóch najwyższych ocen, znajduje się także „Solidny artykuł”, „I poziom”, „II poziom”, „III poziom” i „IV poziom”. Polskojęzyczna Wikipedia obok dwóch najwyższych ma trzy dodatkowe klasy: „Czwórka” ("Poprawny"), „Start” ("Dostateczny") i „Zalążek".
Pomimo tych samych nazw, równoważne klasy między wersjami językowymi mogą różnić się sposobem oceny artykułów (innymi słowy - mają różne standardy oceny jakości). Na przykład, w niektórych wersjach językowych istnieje ograniczenie długości artykułu dla wysokich ocen. Dlatego każda wersja językowa może mieć własny model jakości, nawet jeśli porównywane wersje językowe mają taką samą liczbę ocen.
Dodatkowym problemem jest duża liczba artykułów bez oceny jakości. Niektóre wersje językowe zawierają ponad 90% artykułów bez oceny jakościowej. Poniżej znajduje się tabela porównawcza dla niektórych wersji językowych Wikipedii (w kolejności: białoruski, niemiecki, angielski, francuski, polski, rosyjski, ukraiński).
W celu zdefiniowania wymiarów jakościowych Wikipedii, należy wziąć pod uwagę podobieństwo tej witryny do tradycyjnych encyklopedii oraz serwisów Web 2.0. Z jednej strony artykuły Wikipedii są tworzone w encyklopedycznym stylu. Z drugiej strony Wikipedia jest zbudowana w sposób umożliwiający współpracę między użytkownikami. Dlatego ta witryna internetowa jest oparta na technologiach Web 2.0.
Poniższy rysunek przedstawia różnice między wymiarami jakościowymi Web 2.0, tradycyjną encyklopedią i Wikipedią. Biorąc pod uwagę kryteria jakości przyjęte przez społeczność Wikipedii, możemy wybrać następujące wymiary (atrybuty) jakości dla artykułów Wikipedii: aktualność, czytelność, kompletność, obiektywność, relewancja, styl, wiarygodność .
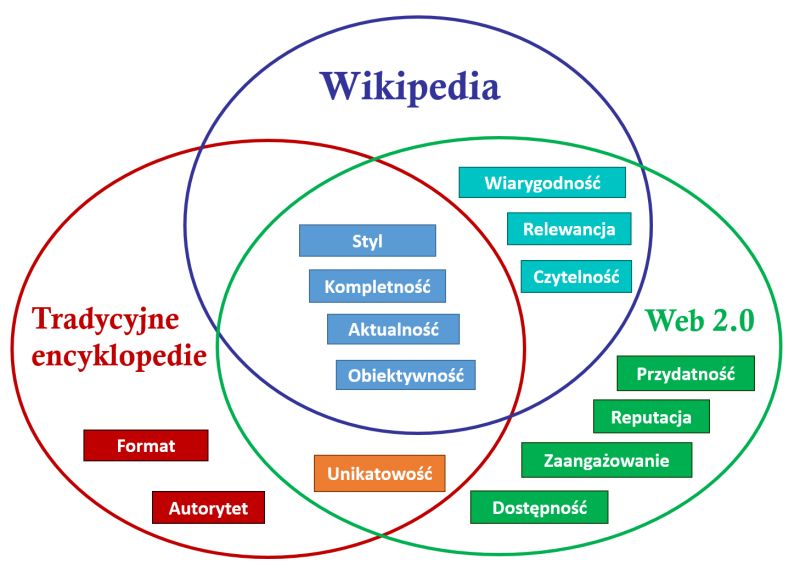
- Aktualność: na ile artykuł opisuje aktualny stan określonej rzeczywistości (stopień aktualności informacji).
- Czytelność: na ile tekst jest zrozumiały i wolny od niepotrzebnej złożoności.
- Kompletność: jak obszerny jest opis tematu w artykule.
- Obiektywność: na ile treść artykułu spełnia kryterium neutralnego punktu widzenia, czy zawiera zdjęcia i inne materiały multimedialne związane z tym artykułem.
- Relewancja: w jakim stopniu artykuł jest istotny (ważny) dla czytelników/użytkowników.
- Styl: sposób zorganizowania treści artykułu.
- Wiarygodność: czy dostarczone informacje można sprawdzić za pomocą wiarygodnych źródeł.
Ważne miary jakości
Przy pomocy algorytmów uczenia maszynowego, możemy określić, które miary (wskaźniki lub parametry) artykułów Wikipedii są najważniejsze dla oceny jakości. Przykład takich parametrów: liczba słów w tekście artykułu, liczba obrazków, odwiedziny artykułu przez określony czas, ile razy artykuł był redagowany itp.
Siedem lat temu opublikowaliśmy wyniki badań, w których wykazaliśmy, że wskaźniki wraz z ich znaczeniem tworzą pewien profil języka, czyli jeden parametr jest ważny dla jednego języka, drugi lepiej charakteryzuje jakość informacji w inna sekcja językowa Wikipedii. Następnie możemy porównać różne języki.

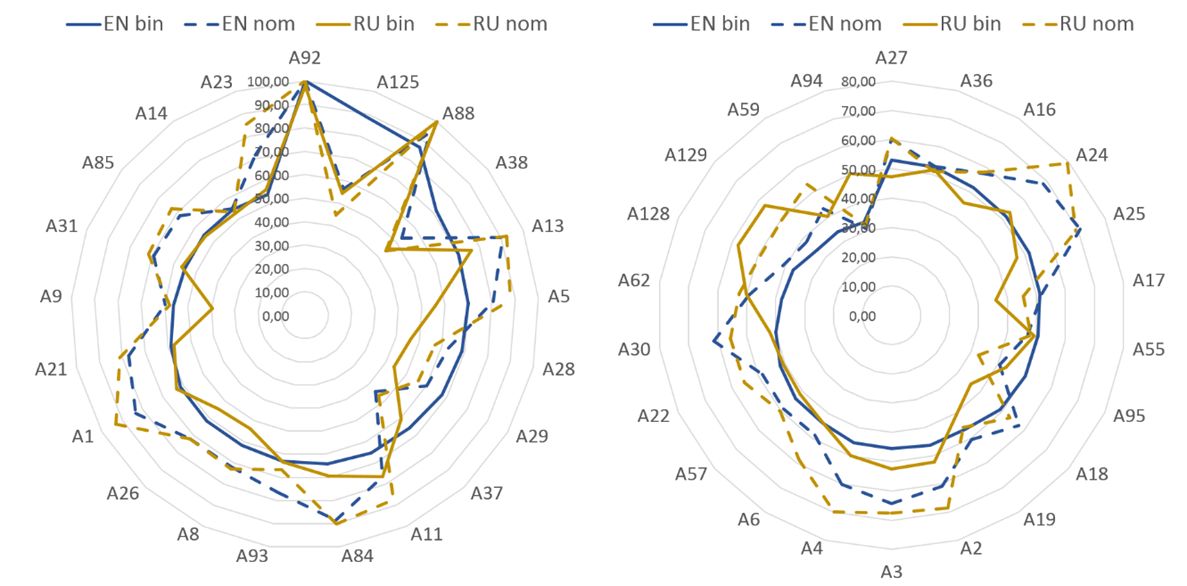
Inny przykład - w mojej pracy doktorskiej wykorzystałem ponad 100 miar do zbudowania modeli jakości dla różnych języków. Poniższy rysunek przedstawia znaczenie wybranych parametrów w modelach prognozowania jakości w angielskiej i rosyjskiej Wikipedii.
Syntetyczny wskaźnik jakości
Okazało się, że niektóre miary były bardzo istotne w modelach jakości artykułów Wikipedii w różnych językach. Takie parametry zwykle korelują pozytywnie z ocenami jakości: długość artykułu, liczba obrazków, przypisy, sekcje, autorzy itp.
Siedem lat temu zaproponowaliśmy metodę oceny jakości artykułu w skali ciągłej (od 0 do 100). Ta metoda wykorzystuje syntetyczny wskaźnik jakości, który zawiera znormalizowane wartości ważnych parametrów artykułu. Normalizacja wybranych miar zależy od wersji językowej Wikipedii, ponieważ wykorzystuje progi zależne od najlepszych artykułów w wybranym języku. Normalizację każdego parametru przeprowadzono zgodnie z następującą zasadą: jeśli wartość rozpatrywanego parametru w danym języku przekracza wartość progową mediany najlepszych artykułów w tej samej wersji językowej, przyjęto ją na 100 punktów; w przeciwnym razie jego wartość skalowano liniowo, aby odzwierciedlić stosunek wartości parametru do średniej. Bardziej szczegółowe informacje o algorytmie i wynikach zastosowania syntetycznego wskaźnika jakości na milionach artykułów Wikipedii można znaleźć w publikacjach naukowych w czasopiśmie Informatics and Computers.
Liczbowa wartość jakości artykułów umożliwia porównywanie jakości artykułów nawet pomiędzy różnymi wersjami językowymi Wikipedii. Dzięki temu można znaleźć tematy (kategorie) artykułów w określonej wersji językowej Wikipedii, które zawierają lepsze informacje.
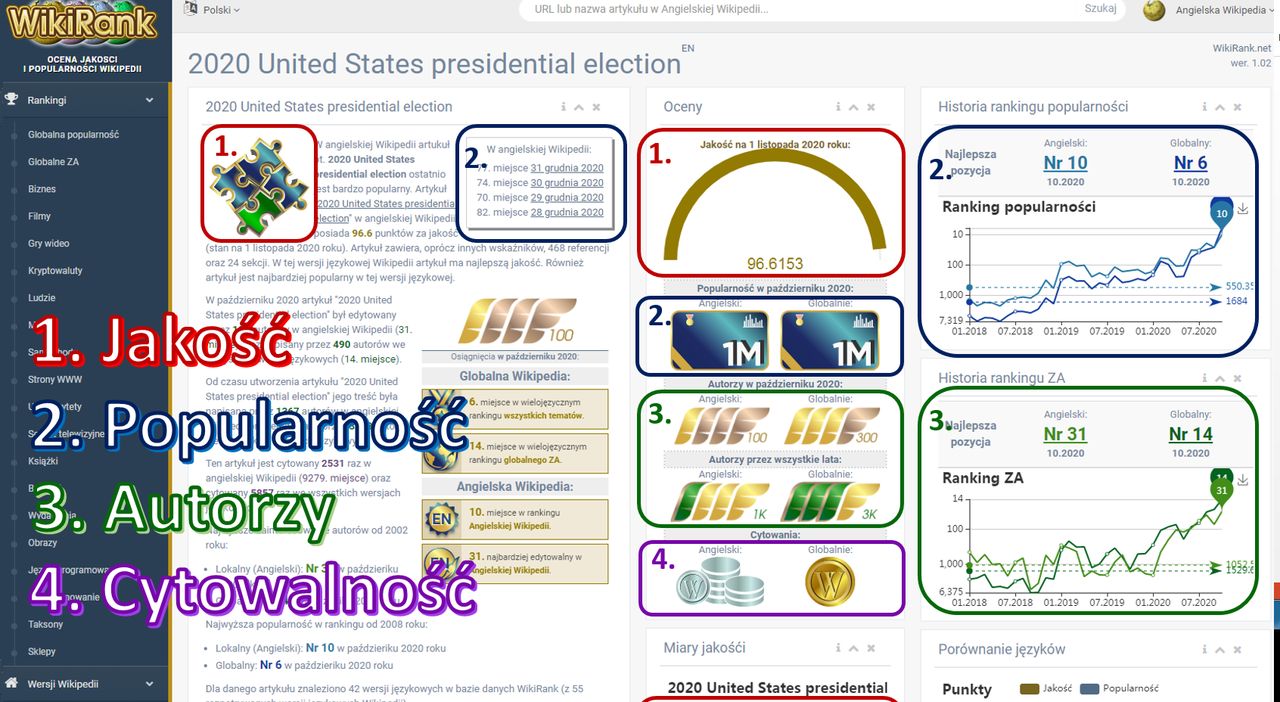
Wyniki oceny jakości, wraz ze wskaźnikami popularności, cytowań i zainteresowań autorów, można wykorzystać do utworzenia indywidualnego profilu dla każdego artykułu Wikipedii w każdej wersji językowej. Przykładowo poniższy obrazek przedstawia taki profil na portalu WikiRank z informacjami o jakości i popularności artykułu „2020 United States presidential election” w angielskiej Wikipedii.
Źródła informacji w Wikipedii
Jednym z najważniejszych czynników wpływających na jakość artykułów Wikipedii jest dostępność wiarygodnych źródeł. Korzystając z linków w przypisach (odnośnikach lub odwołaniach), czytelnicy mogą sprawdzić fakty lub znaleźć więcej informacji na opisany temat. W jednym z naszych ostatnich artykułów przeanalizowaliśmy ponad 40 milionów artykułów z 55 najbardziej rozwiniętych wersji językowych Wikipedii, aby wydobyć informacje o ponad 200 milionach przypisach oraz znaleźć najpopularniejsze i najbardziej wiarygodne źródła.
We wspomnianej publikacji wykorzystaliśmy różne sposoby wyszukiwania i wydobywania informacji o źródłach z artykułów Wikipedii. Na przykład kompleksowe wyodrębnianie opierało się na kodzie źródłowym artykułów (wikikod). Obecności niektórych przypisów nie można bezpośrednio określić na podstawie kodu źródłowego (wiki) artykułów. Czasem bloki lub tabele informacyjne w artykule Wikipedii są przedstawiane tylko jako szablony (linki w kodzie, które umożliwiają pobieranie treści z innych stron Wikipedii). Rysunek przedstawia tę sytuację na przykładzie tabeli z przypisami w artykule Wikipedii o pandemii koronawirusa, który został dodany za pomocą szablonu. W naszym kompleksowym podejściu wzięliśmy pod uwagę zawartość takich szablonów.
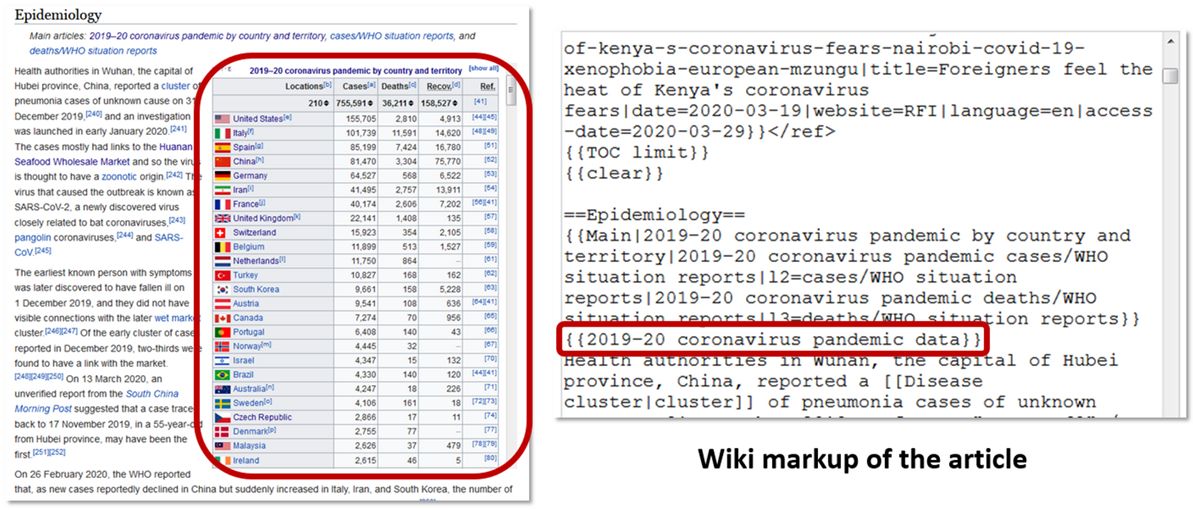
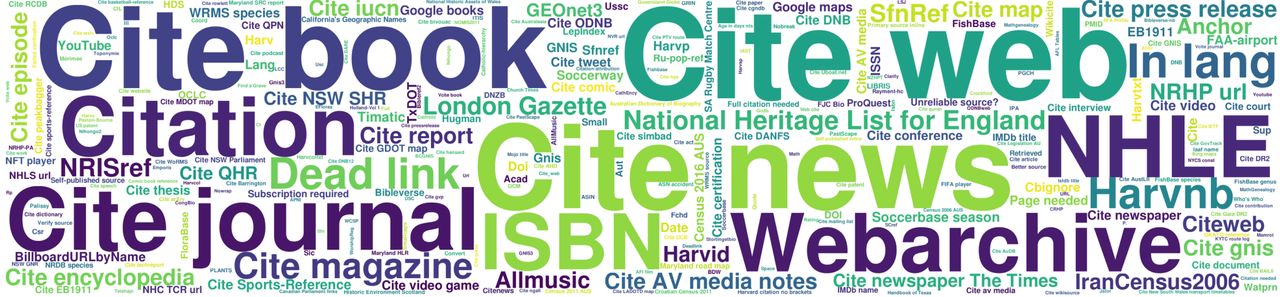
Poniższy rysunek przedstawia najczęściej używane wzorce w ramach tagów „<ref>” w angielskiej Wikipedii. Do najczęściej używanych szablonów w wersjach językowych tej Wikipedii należą: „Cite web”, „Cite news”, „Cite book”, „Cite journal” i inne.
W przypadku polskojęzycznej Wikipedii wśród najpopularniejszych szablonów można znaleźć takie jak: „Cytuj stronę”, „Cytuj książkę”, „Cytuj”, „Cytuj pismo” itp. Poniższy rysunek ilustruje najczęściej używane szablony w znacznikach „<ref>” w polskiej Wikipedii.

Dla innych wersji językowych Wikipedii podobne wykresy można znaleźć w materiałach uzupełniających do publikacji naukowej.
Szablony cytowania
Niektóre często używane szablony w przypisach szczegółowo opisują źródło - mogą zawierać informacje o autorach, wydawcy, dacie publikacji itp. Na przykład dla angielskiej Wikipedii najczęściej wypełniane parametry takich szablonów pokazano na rysunku:

W przypadku polskojęzycznej Wikipedii podobne dane wyglądają następująco:
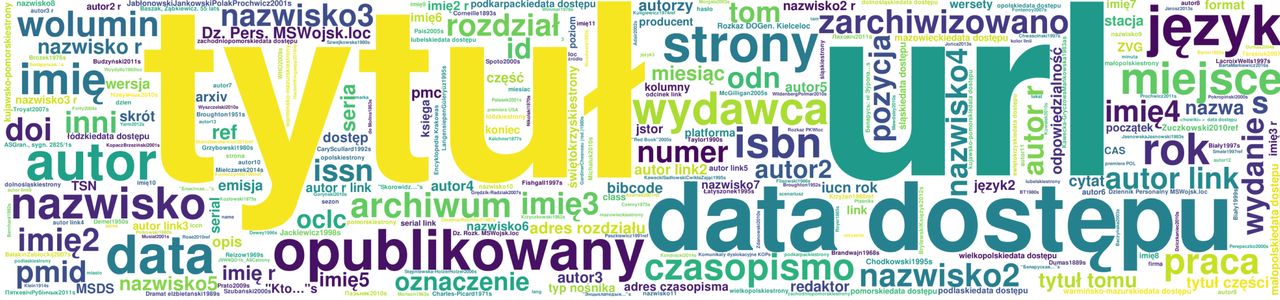
W przypadku innych sekcji językowych wyniki podobnych badań można znaleźć na stronie z dodatkowymi materiałami.
Po przeanalizowaniu takich szablonów z danymi bibliograficznymi możemy znaleźć np. popularnych wydawców w angielskiej Wikipedii. Z ponad 18 milionami tych szablonów, które mają wartość w parametrze „publisher” (wydawca), można wygenerować wykres przedstawiający najczęściej używanych wydawców w źródłach angielskiej Wikipedii.

Niektóre z najpopularniejszych szablonów pozwalają na dodawanie identyfikatorów do źródła, takie jak DOI, JSTOR, PMC, PMID, arXiv, ISBN, ISSN, OCLC i inne. Często takie identyfikatory wskazują na naukowe źródło informacji. Poniższy rysunek pokazuje, która część uwag w niektórych sekcjach językowych Wikipedii zawiera informacje o źródłach z identyfikatorami DOI, ISBN, ISSN, PMID, PMC.
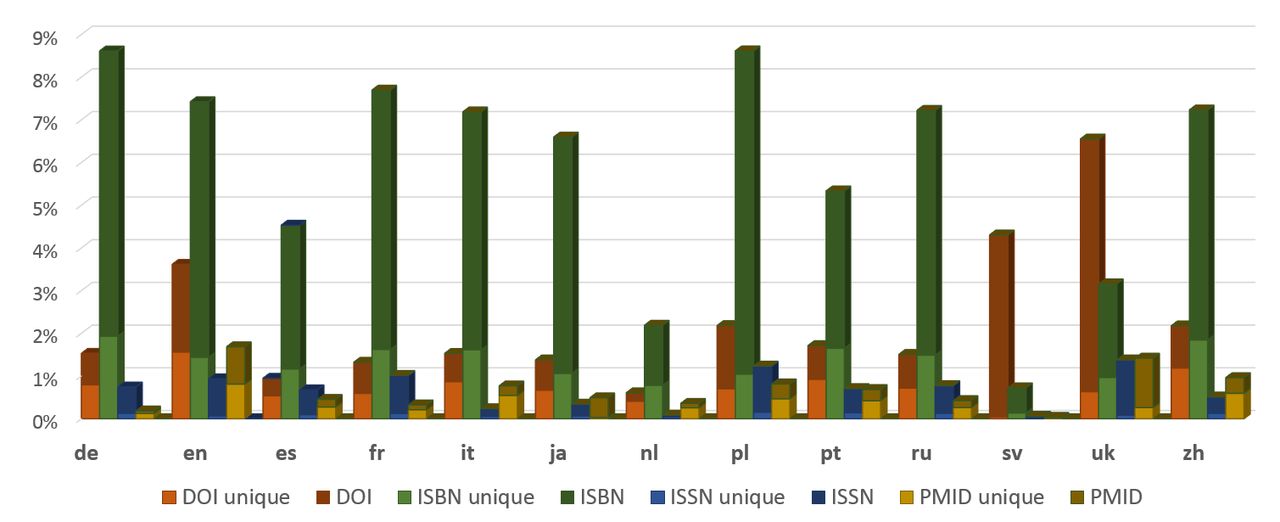
Wyniki pokazują, że najczęściej używanymi identyfikatorami są ISBN i DOI. Jednak w ogólnej liczbie odwołań nie ma więcej niż 10% przypadków. Należy zauważyć, że następuje stopniowy wzrost odsetka cytowań z publikacjami naukowymi.
Modele popularności i wiarygodności źródeł Wikipedii
- Model F - oparty na częstotliwości (F) wykorzystania źródła.
- Model P - oparty na skumulowanych odsłonach (P) artykułu, w którym pojawia się źródło.
- Model PR - oparty na skumulowanych odsłonach (P) artykułu, w którym pojawia się źródło podzielone przez liczbę odnośników (R) w tym artykule.
- Model PL - oparty na skumulowanych odsłonach (P) artykułu, w którym pojawia się źródło podzielone przez długość artykułu (L).
- Modele Pm, PmR, PmL to zmodyfikowane wersje z medianą dziennych odsłon.
- Modele A, AR, AL korzystają z wielu autorów.
Bardziej szczegółowy opis modeli (w tym wzory matematyczne) można znaleźć w publikacji.
Przyjrzyjmy się modelowi F, który pokazuje częstotliwość korzystania ze źródła, czyli jak często analizowana domena pojawia się w adresie URL odwołań. Ta metoda była często wykorzystywana w pokrewnych pracach naukowych. W tym miejscu bierzemy pod uwagę całkowitą liczbę wystąpień takiego linku, czyli jeśli to samo źródło jest cytowane 3 razy, liczę się jako 3.
W przypadku angielskiej Wikipedii najczęściej używane witryny w odsyłaczach przedstawiono na poniższym rysunku:

Jeśli spojrzymy na wyniki oceny źródła w oparciu o model PR, to liderzy angielskiej Wikipedii będą wyglądać trochę inaczej:

W materiałach uzupełniających do publikacji można znaleźć bardziej rozbudowane wyniki dla różnych wersji językowych z wykorzystaniem modelu F i modelu PR.
Jak widać, w zależności od modelu oceny popularności i wiarygodności możemy uzyskać różne wyniki dla tego samego źródła. Badania wykazały, jak różne mogą być również oceny wiarygodności w zależności od wersji językowej. Poniżej znajduje się tabela porównawcza pozycji w rankingu popularności i wiarygodności dla czterech źródeł: nytimes.com, spiegel.de, lemonde.fr, elpais.com. Każde źródło zostało ocenione pod kątem innej wersji językowej Wikipedii i różnych modeli.
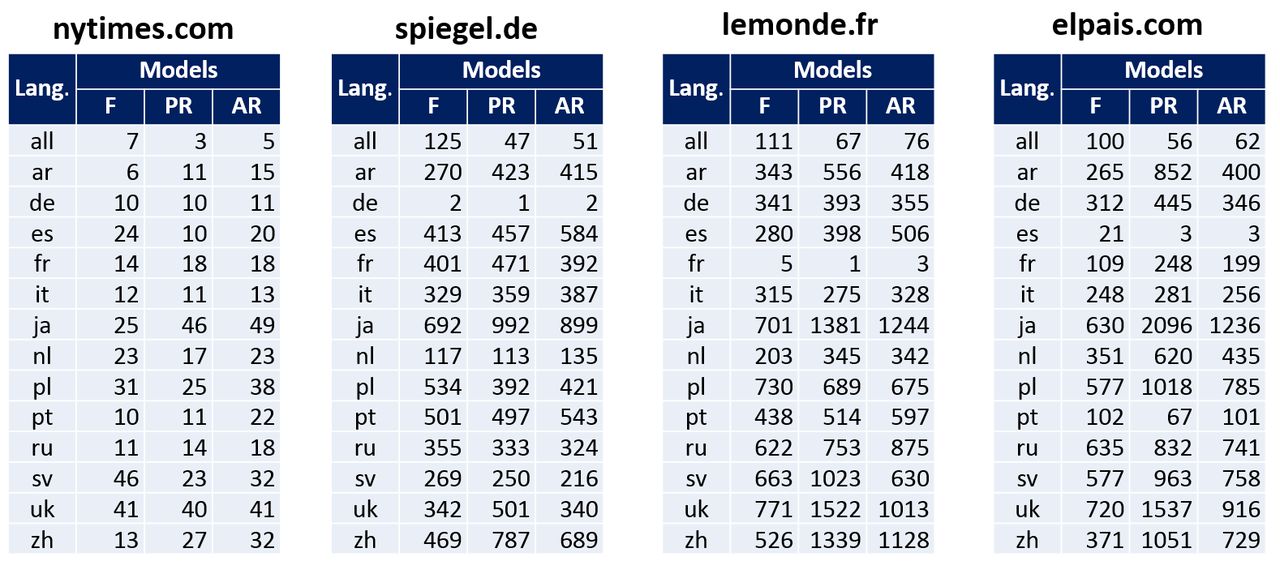
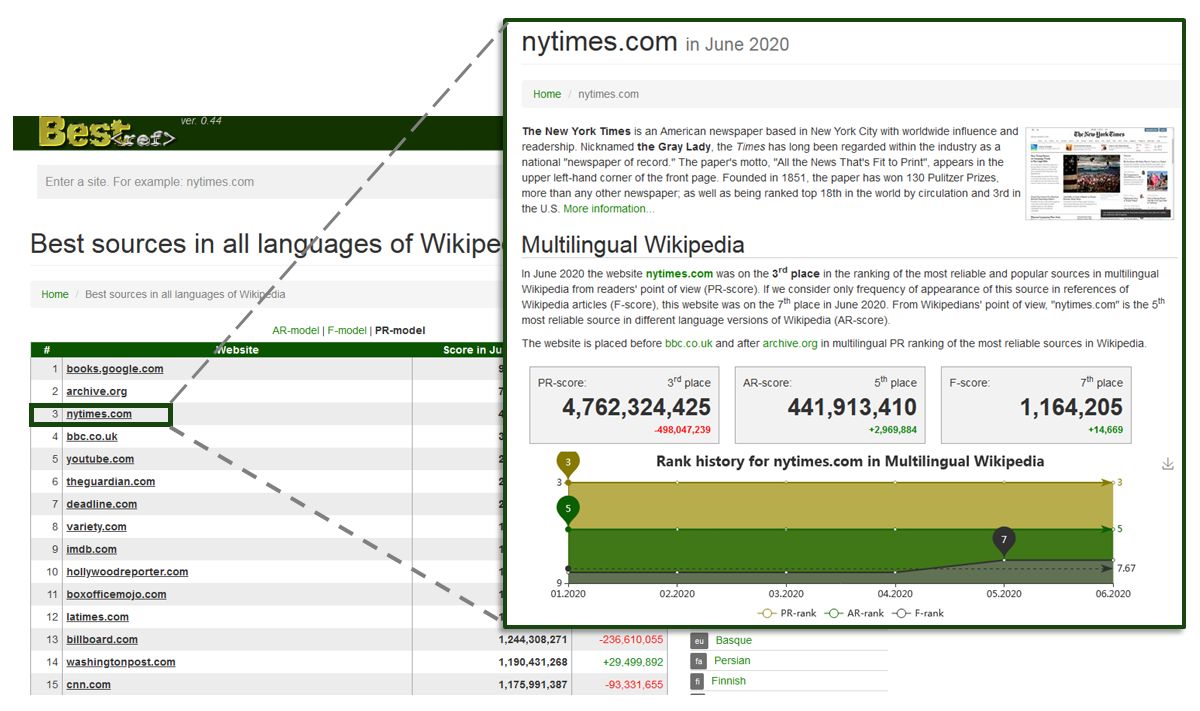
Jeśli będziemy rozpatrywać witryny (domeny) jako źródła, to ich liczba sięga ponad miliona unikatowych. Część wyników oceny każdego źródła Wikipedii jest dostępna na portalu BestRef. Dla każdego źródła w tym projekcie istnieje oddzielny profil, który przedstawia wyniki oceny przy użyciu różnych modeli i w ramach każdej sekcji językowej Wikipedii. W przypadku powyższych czterech źródeł są to odpowiednio nytimes.com, spiegel.de, lemonde.fr, elpais.com. Osobno można zobaczyć listę najpopularniejszych i wiarygodnych źródeł w określonej wersji językowej (na przykład polskojęzyczna Wikipedia). Poniżej znajduje się przykład listy źródeł i profilu dla wybranej witryny.
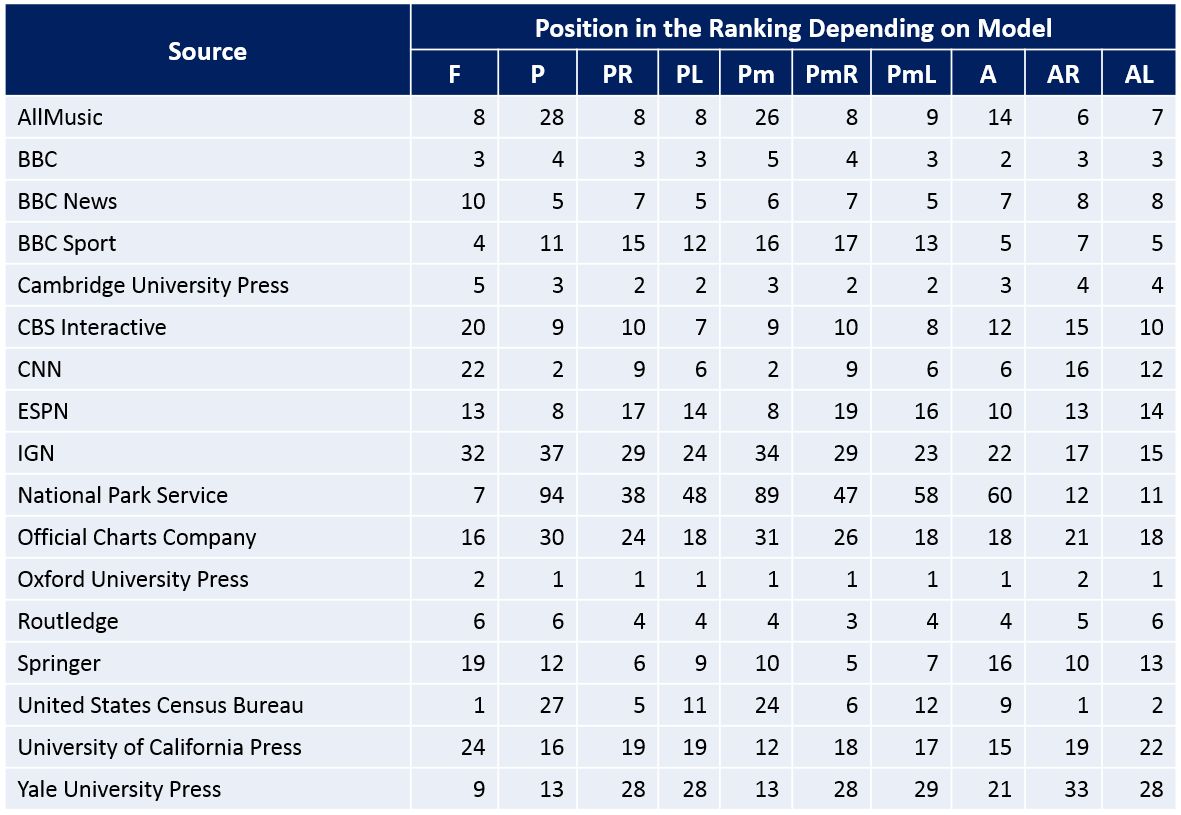
Korzystając z różnych modeli popularności i wiarygodności, możemy ocenić nie tylko domeny, ale także określone typy źródeł. Na przykład, na podstawie obszernych informacji bibliograficznych z szablonów w przypisach, uszeregowaliśmy wszystkich wydawców w angielskiej Wikipedii. Poniższa tabela przedstawia najpopularniejszych i najbardziej wiarygodnych wydawców z pozycjami rankingowymi według modelu.
Narzędzia do oceny jakości i wiarygodności
Wyniki niektórych badań zostały włączone do odrębnych projektów publicznych. Co więcej, istnieją nawet rozszerzenia przeglądarki, które pozwalają „na miejscu” sprawdzić jakość artykułów Wikipedii i ich źródła. Na przykład możesz użyć wtyczki BestRef do przeglądarki Chrome, aby sprawdzić wiarygodność źródeł. Prezentacja wideo tej wtyczki:
Można użyć wtyczki WikiRank dla Chrome i Firefox, aby ocenić oraz porównać jakość i popularność artykułów Wikipedii. W tym filmie pokrótce pokazano, jak to działa.
Osobno dostępne jest rozszerzenie do oceny jakości infoboksów (kart informacyjnych) w przeglądarce Chrome. Na prezentacji wideo można zobaczyć jak to działa.
Co dalej?
Proponowane modele jakości informacji, popularności i wiarygodności źródeł mogą pomóc wzbogacić różne wersje językowe Wikipedii oraz inne bazy wiedzy (takie jak DBpedia, Wikidane) o informacje wyższej jakości. Planuje się włączenie niektórych metod do projektu GlobalFactSync (GFS). Celem projektu GFS jest synchronizacja danych faktograficznych we wszystkich rozdziałach językowych Wikipedii i Wikidanych. W tym przypadku dane faktyczne definiuje się jako określoną „porcję” informacji, tj. wartości danych, takie jak „współrzędne geograficzne”, „liczba ludności” (dla miast), „data urodzenia”, „wzory chemiczne” dołączone do obiektu (w artykule z Wikipedii lub w Wikidanych) i najlepiej z odniesieniem do źródła (pochodzenia tych informacji).
Ponadto informacje o wiarygodności źródeł mogą pomóc w ulepszaniu modeli oceny jakości artykułów Wikipedii. Może to być szczególnie przydatne przy porównywaniu niespójnych faktów między wersjami językowymi artykułów Wikipedii. Dodatkowo jednym z obiecujących obszarów przyszłych badań jest stworzenie publicznie dostępnych narzędzi, które pozwoliłyby na rekomendację najlepszych źródeł dla poszczególnych wypowiedzi i wybranych tematów w różnych wersjach językowych Wikipedii.
Zaproponowane w badaniach modele nie są idealne i można je ulepszyć - istnieje „ogromne pole manewrów”. Im dokładniej badamy ten obszar, tym więcej znajdujemy problemów i możliwych rozwiązań.
Więcej informacji na temat badań naukowych w tym kierunku można znaleźć na stronie WikiQ. Jeżeli ktoś jest zainteresowany tym tematem - jesteśmy gotowi rozważyć współpracę w tym kierunku. Pytania i sugestie można zostawić tutaj w komentarzach lub skontaktować się ze mną w inny sposób.
Literatura
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2020). Modeling Popularity and Reliability of Sources in Multilingual Wikipedia. Information, 11(5), 263. doi: 10.3390/info11050263
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2019). Multilingual Ranking of Wikipedia Articles with Quality and Popularity Assessment in Different Topics. Computers, 8(3), 60. doi: 10.3390/computers8030060
- Lewoniewski, W. (2019). Measures for Quality Assessment of Articles and Infoboxes in Multilingual Wikipedia. In International Conference on Business Information Systems (pp. 619–633). Springer, Cham. doi: 10.1007/978-3-030-04849-5_53
- Lewoniewski, W. (2018). Metoda porównywania i wzbogacania informacji w wielojęzycznych serwisach wiki na podstawie analizy ich jakości. Praca doktorska
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2017). Relative Quality and Popularity Evaluation of Multilingual Wikipedia Articles. Informatics 2017, 4(4), 43. doi: 10.3390/informatics4040043
- Lewoniewski, W. (2017). Enrichment of Information in Multilingual Wikipedia Based on Quality Analysis. In International Conference on Business Information Systems (pp. 216–227). Springer, Cham. doi: 10.1007/978-3-319-69023-0_19
- Lewoniewski, W., Węcel, K., Abramowicz, W. (2017). Analysis of references across Wikipedia languages. In International Conference on Information and Software Technologies (pp. 561–573). Springer, Cham. doi: 10.1007/978-3-319-67642-5_47

![Mercedes wśród kamerek internetowych. Logitech MX BRIO [Recenzja Premierowa]](https://v.wpimg.pl/NTc5LmpwYTUCVzpeXwxsIEEPbgQZVWJ2Fhd2T19Cd2MbBn9bXwMrNwsbOx0TEyB6E1ljBB0QYWMFByhUFhN6eVFTdF1dQyg3Wxh1VBRPYzYABn4IEUR4MVYCdUMaByl2Hg)
![Smartfon z wysokiej półki w przystępnej cenie. Motorola Edge 50 pro [Recenzja]](https://v.wpimg.pl/NWQzLmpwYTYwGDpeXwxsI3NAbgQZVWJ1JFh2T19Cd2ApSX9bXwMrNDlUOx0TEyB5IRZjBB0QYWU1TXVdFBUremFPLVldQys0Yld0WEVAY2Y3Tn1VE0R_M2Qef0MaByl1LA)
![Minimalistyczny mikrofon dynamiczny do 300 zł. Genesis Radium 350D [Recenzja]](https://v.wpimg.pl/MGNiLmpwYiYvCzpeXwxvM2xTbgQZVWFlO0t2T19CdHA2Wn9bXwMoJCZHOx0TEyNpPgVjBB0QYiQoD31eQxV1aiheeFtdQ3p_fER0X0QWYH8qXHkJSUApI34KLkMaByplMw)
![Komfortowe słuchawki dla graczy ceniących wygodę. Genesis Toron 531 [Recenzja]](https://v.wpimg.pl/NTIyLmpwYTUoGzpeXwxsIGtDbgQZVWJ2PFt2T19Cd2MxSn9bXwMrNyFXOx0TEyB6ORVjBB0QYWJ9TShaEUR6eX5OfgxdQy81eVQtXEcSY2N_SH9fEhUtZnxLfkMaByl2NA)


![Pojemny i wydajny. Silver Monkey Powerbank 20.000 mAh 100 W [Recenzja]](https://v.wpimg.pl/MzdkLmpwYhsFCTpeXwxvDkZRbgQZVWFYEUl2T19CdE0cWH9bXwMoGQxFOx0TEyNUFAdjBB0QYhlRWHhaR0QpVwdadVRdQ39DVkZ1WUJHYEoGWipYQUcoTldcKEMaBypYGQ)