


Nvidia przechodzi na MCM? Oto pomysł na duże rdzenie w relatywnie umiarkowanej cenie
MCM, aka Multi Chip Module, to koncepcja tworzenia dużych układów krzemowych z wielu małych modułów. Korzystają z niej już m.in. procesory z rodziny AMD Zen i serwerowe Intel Cascade Lake-AP. Następna w kolejce do wdrożenia wielomodułowości zdaje się być Nvidia.


W sobotę Twittera obiegł schemat blokowy przedstawiający ponoć rdzeń graficzny Nvidii kolejnej generacji, opisywanej nazwą kodową Hopper. Jak wynika z pogłosek, chodzi tu o sukcesora serii Ampere, która to z kolei ma zastąpić obecne turingi. Nie jest to więc plan na najbliższy rok, a bardziej odległa przyszłość. Ale przedstawione założenia wyglądają niezwykle ciekawie.
Aktualnie największy produkowany przez Nvidię czip to Volta GV100. Powstaje w procesie litograficznym klasy 12 nm FFN i zawiera bagatela 21,1 mld tranzystorów, ulokowanych na powierzchni 815 mm². To imponujące. Jednak tak duża powierzchnia rodzi dwa zasadnicze problemy. Po pierwsze, z wafla o średnicy 300 mm, a takie się obecnie stosuje, można wyciąć maksymalnie 64 czipy. Po drugie, matryce do wytwarzania układów w najnowszej technologii 7 nm EUV, wykorzystującej daleki ultrafiolet, mają ograniczony rozmiar.
Nie wspominając już o tym, że uzysk z wafla nigdy nie wynosi 100 proc., przez co część wyprodukowanych układów trzeba wyrzucić. Koszty produkcji stają się ogromne.
Karta graficzna z klocków LEGO
Co innego, gdyby pociąć giganta na cztery mniejsze podukłady. Z tego samego wafla można byłoby wyprodukować aż 285 modułów, co daje 71 rdzeni. Mówiąc obrazowo, 11 proc. wyższą efektywność produkcji. Mniej bolesna zarazem stałaby się utylizacja egzemplarzy niesprawnych. Do śmietnika szedłby nie cały rdzeń, ale pojedynczy moduł. Korzyści są niezaprzeczalne.
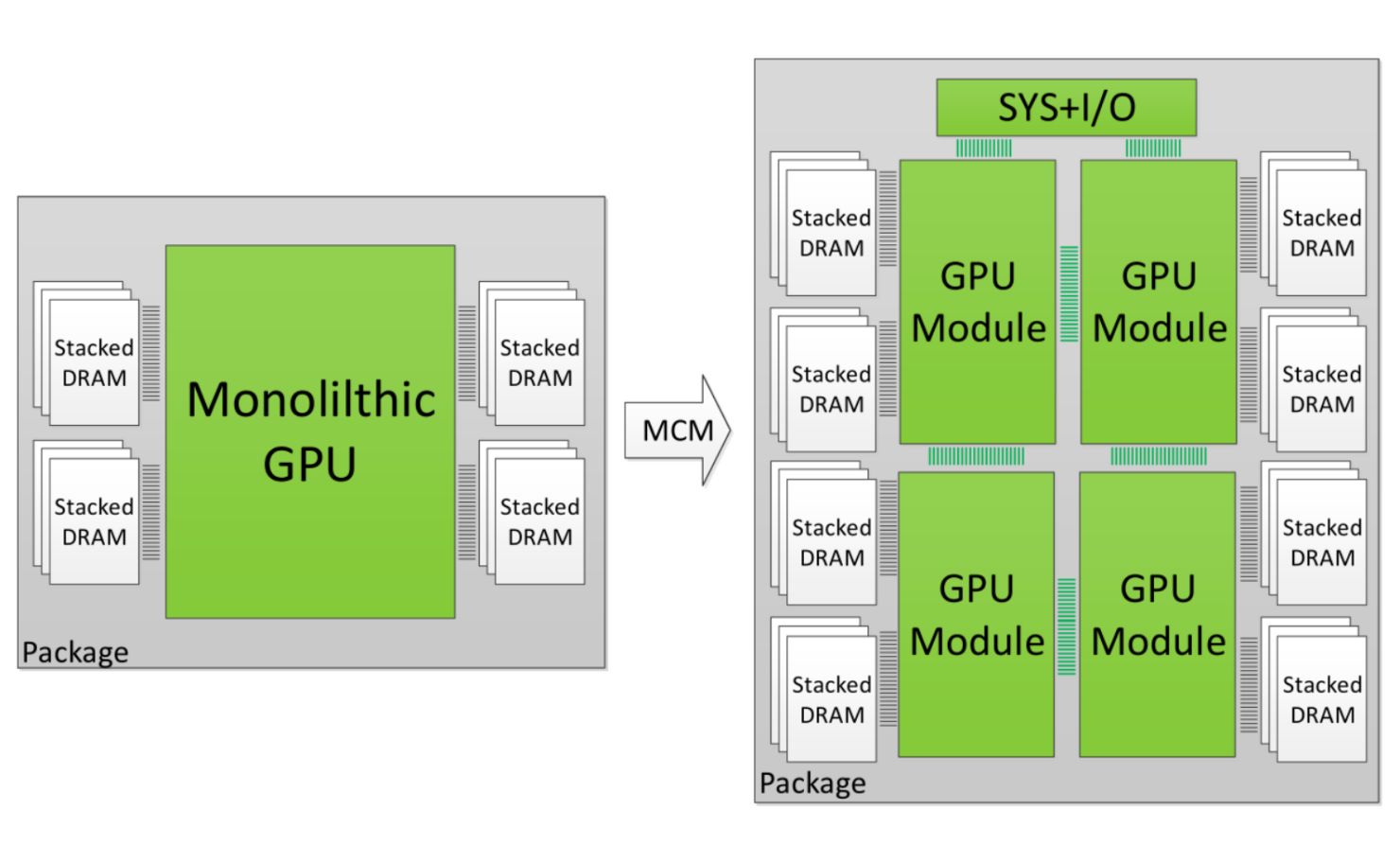
Jest tylko jeden, ale za to bardzo istotny problem: inżynierowie muszą opracować interkonekt, który pozwoli na synchronizację modułów MCM bez generowania nadmiernych opóźnień. Aby procesor, czy to centralny czy graficzny, działał jak spójna całość, wszystkie jednostki wykonawcze muszą mieć dostęp do tej samej puli pamięci, także podręcznej najniższych poziomów. Tymczasem najszybszy cache to taki, który znajduje się bezpośrednio przy rdzeniu. Stąd o ile wielomodułowość na pewno kusi księgowych, o tyle dla inżynierów stanowi twardy orzech do zgryzienia.
Trudno się dziwić, że Nvidia chce sobie dać więcej czasu na opracowanie dostatecznie efektywnego rozwiązania. Z drugiej strony, gdyby przedstawiony plan zakończył się sukcesem, to na rynku kart graficznych odbędzie się prawdziwa rewolucja. Zobaczymy czipy znacznie większe niż dzisiaj, a co za tym idzie znacznie wydajniejsze. A przy tym nie droższe, przynajmniej w produkcji.