







Oczekiwania względem rozwiązań 3D zostały podkręcone przez działy marketingu do tego stopnia, że gdy owa technologia w końcu trafiła do masowego odbiorcy, efektem było powszechne rozczarowanie. Poza inżynieryjną specjalizacją, jaką okazały się drukarki trójwymiarowe, 3D dość mocno oklapło. Kinowe seanse 3D, wymagające tych nieszczęsnych okularów, wcale nie są najpopularniejszą ofertą. Telewizory Smart TV z funkcją 3D w praktyce wymarły, pozostają jedynie „trochę-smart” TV: wystarczająco mądre, by rzucać na nie obraz z telefonu, ale na tyle głupie, żeby nie obsługiwać sklepu z aplikacjami. Ale bez obaw, niedługo wkroczy nowe, „lepsze” 3D. Jakże kojący jest zatem fakt, że większa liczba wymiarów przestrzennych jest nam niedostępna.
Tak to jest, gdy coś reklamuje się jako rewolucję jeszcze przed powstaniem. Nierealistyczne oczekiwania przegrywają z rzeczywistością: w kwestii wspomnianego 3D, ludzie zaczęli oczekiwać futurystycznych hologramów, a nie lekkiego efektu wypukłego rozmycia. Wywołującego w dodatku migrenę. Stąd też w przypadku innej „technologii przyszłości”, czyli coraz prężniej rozwijających się metodyk opartych o sztuczną inteligencję, kampania popularyzacji przebiega już w znacząco inny sposób. Oczekiwania, owszem, są podbijane, a o „big data” i „głębokim uczeniu” nie da się już słuchać, ale tym razem rynek nie forsuje rażąco niedokończonych rozwiązań, opisując je jako rzekomy przełom. Luka jest wypełniana właśnie owym zalewem „buzzwords” – proste mechanizmy adaptacji są reklamowane jako oparte o mityczny deep learning. Na tej samej zasadzie można reklamować linię płatków śniadaniowych poprzez podkreślanie, że nie zawierają azbestu.

Przyswajalność terminologii marketingowej jest jednak ograniczona, czasem trzeba pokazać choć fragment jakiejś technologii. Postacią AI, która najpowszechniej przeciekła do elektroniki użytkowej, są cyfrowe asystentki (asystenci?), jak Siri, Cortana i interfejs Google Now. Koncepcja inteligentnych, upersonifikowanych asystentów, zwanych niegdyś „agentami” nie jest nowa. Przez wiele lat było to pojęcie z zakresu projektowania interfejsów, a sama algorytmika „pod spodem”, wedle założenia, miała być uproszczona i reagować np. na zamknięty zbiór słów-kluczy. W ten sposób działały pierwsze wersje niesławnego Spinacza z pakietu Office. Dopiero z biegiem czasu do instytucji „agenta” rozpoczęto dodawanie niestandardowych interfejsów, obsługi języka naturalnego i pracy opartej o głębokie uczenie. Progres, jaki dokonał się między spinaczem z Worda 97 a dzisiejszą Cortaną, jest olbrzymi i niezaprzeczalny.
Problem polega na tym, że obecne cyfrowe asystentki dalej są głupie jak but. Zapraszam do przeprowadzenia testu: proszę wziąć swój telefon, a następnie spróbować dodać głosowo spotkanie do kalendarza. Następnie wyszukać rok premiery płyty „Demon Days” zespołu Gorillaz. A na koniec, zmienić godzinę, na którą ustawiony jest budzik. Wykonanie owego prostego ciągu czynności to w dalszym ciągu horror. Nawet, jeżeli będziemy próbować mówić po angielsku. I nawet, jeżeli zamiast mówienia, po prostu napiszemy, o co nam chodzi. Niezależnie od obranej taktyki, efekty będą żenujące.
Składa się na to spory zestaw powodów. Po pierwsze, mimo nabytej ostrożności, działy promocji dalej usiłują sprzedać więcej, niż to obecnie możliwe. Po drugie, termin „sztuczna inteligencja”, mocno już przetworzony przez kilka dekad oddziaływania na popkulturę, nasuwa skojarzenia z czymś bardziej złożonym, niż tępawy dyktafon. Każe oczekiwać narzędzia o niemal ludzkim poziomie interakcji. Tymczasem taki Google Now potrafi np. wysyłał na stronę Wikipedii dot. firmy Ikarus gdy szukamy przystanków autobusowych. Innymi słowy, nie oferuje oczekiwanego poziomu. Poza tym, obsługa ludzkich kanałów komunikacyjnych jest zawrotnie trudna. Już samo rozpoznanie pisma i wydzielenie słów z mowy to nie lada wyczyn, a potem jeszcze trzeba to „zrozumieć”, biorąc poprawkę na nieścisłości języka, różnice kulturowe, mowę potoczną, wieloznaczność oraz niekoniecznie porażający intelekt użytkownika. Niemałą rolę pełni też mechanizm kontrastu: oto jeszcze wczoraj w reklamach dostawałem propozycje produktu, którego dopiero planowałem zacząć szukać w sklepach, a dziś Siri ma trudności ze zrozumieniem, że chcę przepis na sernik wiedeński. Sernik! Matko jedyna, czy ja naprawdę chcę od życia zbyt wiele! Z torebki sobie zrobię. Bez łaski.
Tymczasem dziś oczekujemy od elektroniki o wiele więcej. Oprogramowanie potrafi nas wszak nierzadko zaskoczyć swoją błyskotliwością. Jest to jednak mylące. Algorytmicznie wysnuwane wnioski z prostych zależności mogą pozornie wyglądać na niezwykle złożone i „mądre”. Tak samo, jak proste reguły Conway’owskiej Gry w Życie pozwalają wytworzyć bardzo skomplikowane szlaki automatów komórkowych, tak nasze wyszukiwania w sklepach, zestawione z codzienną trasą z pracy do domu, skutkują dokładniejszymi powiadomieniami w zniżkach w sklepie z ciuchami. Trudności pojawiają się dalej. Ten sam przerażająco przenikliwy w swych kapitalistycznych podbojach wszech-system ma jednocześnie poważne trudności z odróżnieniem żółwia od strzelby. Innymi słowy, dysponujemy algorytmiką na tyle zaawansowaną, że na podstawie naszych „śladów cyfrowych” da się o nas napisać całkiem dokładną biografię, z rozdziałami o przyszłości włącznie – ale rozpoznanie pisma z nagryzmolonej w pośpiechu listy zakupów będzie wyczynem, na którym polegną wszystkie centra danych NSA.
To oczywiście kojąca myśl. Miło czasem nabrać przekonania, że Bunt Maszyn jest jednak odwołany, a Dzień Sądu przełożono, gdy Roomba zakleszcza się na dywanie i wysyła powiadomienie push, że potrzebuje naszej pomocy. Ale ta urocza nieporadność kiepsko się sprzedaje. Gdy „Alexa, wpisz mi wizytę u dentysty do kalendarza” nie działa za ósmym razem albo, co gorsza, informuje o powodzeniu, w tle robiąc coś kompletnie innego, wizerunek dostawcy asystenta cierpi. Ponieważ lepsza sztuczna inteligencja ponownie dopiero nadchodzi i nadejść nie umie, rynek musi radzić sobie inaczej. Taki Google lub Amazon nie może, niczym lekarz praktykant („Nie mam pojęcia, co Panu jest, ale mogę Panu narysować Cykl Krebsa!”), powiedzieć że co prawda ustalanie kalendarza nie działa, ale za to da się zamawiać pizzę w ośmiu miastach. Nie może, bo zostanie wyśmiany. A zostanie wyśmiany, bo wstydliwie próbował już nie raz.
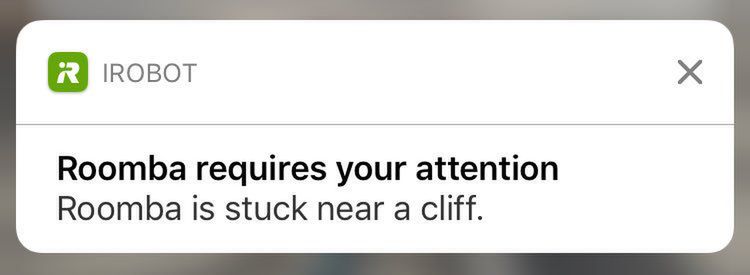
Stąd też potrzebne są półśrodki. Nie ma w tym nic złego, półśrodki to naturalny etap przejściowy w każdej technologii. Pierwsze smartfony udawały, że potrafią renderować pełne strony internetowe, a w praktyce serwowały przygotowywany zdalnie obrazek. Klasyczne Windowsy przez wiele lat udawały wielozadaniowość, uruchamiając wszystkie zadania w jednej wielkiej pętli (gdy któreś z nich ulegało awarii, cały łańcuszek mógł się koncertowo wyłożyć). Pierwsza konsola do gier – Magnavox Odyssey – wymagała zakładania na ekran telewizora półprzezroczystych nakładek z planszami. I to wszystko jest OK. Technologia nie czeka, tylko stosuje podejście „fake it ‘till you make it”, ponieważ świat jest spragniony postępu technicznego.
O jakich półśrodkach mowa? Otóż w skrócie, Siri „to po prostu jakiś koleś, który tego wszystkiego słucha”. To oczywiście dość mocne uproszczenie, ale jest w nim trochę prawdy. Frazy wypowiadane do słuchających, cyfrowych asystentów, są bowiem przetwarzane wieloetapowo. Część tych etapów następuje po stronie lokalnej (urządzenie), a część po zdalnej (chmurowy „backbone”). To właśnie zdalne przetwarzanie ma być oparte o to nieszczęsne głębokie uczenie. Wyrażając obowiązkową zgodę na udział w programie polepszania jakości usług, godzimy się na upload próbek głosowych do chmury obliczeniowej producenta, która to za pomocą własnościowych (lub nie) algorytmów usiłuje jak najwięcej zrozumieć z naszego niekoherentnego bełkotu. Niestety, uczenie maszynowe i algorytmika wnioskowania potrafią się czasem zapędzić w zły kąt i zacząć gadać bzdury. Wystarczy, że metoda największego spadku „spadnie” nie tam gdzie trzeba. Dlatego algorytmom trzeba pomagać. Potrzebna jest instytucja nauczyciela – dostawcy danych referencyjnych, dokonujących korekty modelu. Czasem jest to Captcha: oznacz wszystkie obrazki, na których znajduje się śmigłowiec. A czasem jest to wynajęty gość w słuchawkach, który dostaje próbkę dźwiękową oraz sugestię rozpoznanego wzorca i ma oznaczyć, czy rozpoznanie było trafne, czy nie.
Z akademickiego punktu widzenia i dziedziny zwanej „sztuczną inteligencją” nie ma w tym nic zaskakującego: byle sieć neuronową trzeba przecież wytrenować w procesie iteracyjnym. Bardziej kosmiczne metody, jak ukryte łańcuchy Markowa, również potrzebują bazy referencyjnej. Ta oczywistość ginie jednak podczas serwowania algorytmu jako produktu dla szerokiego odbiorcy. Udostępnianie próbek audio może się wtedy wydawać szokujące, mimo że nie powinno.
Informacje na ten temat pojawiają się z mniejszym lub większym hukiem od czasu do czasu. Trzy lata temu na Reddicie pojawił się wątek autorstwa sfrustrowanego pracownika jakiegoś centrum obróbki danych. Los (a raczej ekonomia) skazał go na wysłuchiwanie rzeczy wypowiadanych do cyfrowych asystentek. A że ludzie potrafią być zawrotnie ordynarni, bywa to bolesne dla duszy.
Takie słuchanie i poprawianie próbek to jedynie mechanizm wspomagania procesów przejściowo niedoskonałych. Czasami jednak cały model biznesowy, rzekomo wykorzystujący sztuczną inteligencję, jest w praktyce w całości oparty na oszustwie i nie ma mowy o żadnym AI. Zamiast tego zatrudnia się po prostu armię ludzi. Firma X.ai, wedle doniesień Bloomberga, zatrudniała tak wielu „nauczycieli” AI i obciążała ich pracą tak bardzo, że podawało to w wątpliwość skuteczność i w ogóle istnienie algorytmu, który miał być uczony. W praktyce sprowadzało się to ciągłej pracy kilkuset osób codziennie udających, że są czat-botami. Była ona rzekomo jeszcze bardziej drenująca psychicznie, niż wysłuchiwanie „Siri, kochasz mnie?” dwieście razy dziennie, co musiał znosić wyżej wspomniany pracownik Reddita.
Aplikacja Dialpad, chmurowy telefon, zawiera funkcję automatycznego konwertowania nagrań z poczty głosowej na wiadomość tekstową. Zrobiła ona na mnie nie lada wrażenie, ponieważ zaskakująco poprawnie zapisała nagraną wypowiedź nacechowaną silnym hinduskim akcentem. Jednakże doniesienia takie, jak afera z firmą SpinVox, posądzoną o ręczne przepisywanie wiadomości przez pracowników, każą zastanowić się, czy przypadkiem tamto „hinduskie” nagranie nie zostało transkrybowane przez… innego Hindusa, pracującego wraz z setką innych nad udawaniem sztucznej inteligencji i ukrywaniem tego przed akcjonariuszami.
Czasami oszustwo jest półotwarte: Google (i jego dział YouTube) oraz Twitter mówią o wykrywaniu spamu, mowy nienawiści, botów i fake news’ów za pomocą „metod wspomaganych głębokim uczeniem” i przyznają, że ich skuteczność sięga maksymalnie czterdziestu procent. Nie jest to wyrażone wprost, ale płynie stąd jedyny możliwy wniosek, że pozostała część pracy nad moderacją jest dokonywana przez prawdziwych moderatorów, przeklikujących się przez ogrom treści ręcznie, zza biurek. Można domniemywać, że mimo wspomagania ręcznego, tacy giganci jak Google jednak naprawdę pracują nad skutecznymi mechanizmami AI. I że planują coraz mniej opierać się na ludziach, ale w przypadku sezonowych startupów oraz firm-krzaków z Chin i Indii takiego planu może nie być. A będzie tak, dopóki dwustu moderatorów będzie tańszych, niż pięciu programistów AI. Lepiej być skutecznym natychmiast, ale w żenujący sposób, niż osiągnąć to samo w pełni automatycznie, ale dopiero za dziesięć lat.
Temat nadmiernego wspomagania się ludźmi w przetwarzaniu big data wrócił niedawno do mediów wraz z „odkryciem”, że zewnętrzne aplikacje często mają dostęp do poczty posiadaczy smartfonów, na których są zainstalowane. Szok użytkowników oraz wielu zagranicznych dziennikarzy IT (jakże nisko upadła ta profesja!), podobnie jak w przypadku telemetrii w Windows 10, wskazuje na kompletne niezrozumienie zagadnień związanych z techniką używaną na co dzień nawet przez ludzi, którym naiwnie przypisuje się biegłość w owej dziedzinie.
Miernota mechanizmów AI w kwestii świadczenia szeregu usług i nędzna jakość cyfrowych asystentów, zestawione z niepokojąco wysoką skutecznością kampanii reklamowych opartych o telemetrię i ślad cyfrowy kontrastują ze sobą, w dziwny i nieco przygnębiający sposób. Oto stworzenie naszego modelu preferencji, nakreślenie sieci kontaktów i niemal przewidzenie planu dnia co do minuty okazują się łatwiejsze od poprawnego zrozumienia naszej mowy, nawet całkiem podstawowej. Jesteśmy doprawdy prostymi istotami, nawet jeżeli wielu z nas się za takich nie uważa. Stosujemy jedynie metody komunikacji, które obecnie nie podlegają jeszcze łatwej digitalizacji.
Problem leży jednak gdzie indziej, niż w żenadzie płynącej z zatrudniania „sztucznej sztucznej inteligencji”. Nie chodzi również o kondycję psychiczną owych nieszczęśników-symulantów. Martwi coś innego: dzisiejsi asystenci pracują w trybie ciągłego nasłuchu. Setki tysięcy ludzi dobrowolnie montują w swoich domach świecące walce, bez ustanku słuchające z nadzieją na otrzymanie rozkazu dodania pomidorów do listy zakupów, wyszukania daty urodzin Królowej Elżbiety i innych absolutnie niezbędnych do przeżycia rzeczy. Skoro próbka audio ulega przetwarzaniu zdalnie (z czego wiele osób nie zdaje sobie nawet sprawy), a nasłuch jest ciągły, to wnioski powinny nasuwać się same. Tymczasem dzieje się to bardzo rzadko.
Telefon brytyjskiego ministra obrony ma włączoną Siri w trybie ciągłego nasłuchu. Cortana z Windows 10 też słucha bez przerwy, w ramach usługi Windows Hello. A ile telefonów z Androidem czeka bez ustanku na „OK Google, pokaż mi animowane koty”? Zdecydowanie zbyt wiele. Telefony słuchają nas znacznie częściej, niż nam się wydaje. Wszystkie moje aplikacje mają zakaz korzystania z mikrofonu, doraźnie zdejmuję go dla komunikatorów, gdy akurat chcę porozmawiać i żyję naiwnością, że ten przełącznik praw dostępu, który przesuwam w owym celu rzeczywiście coś daje, a nie jest atrapą. Ale obsługa mikrofonu jest dziś wbudowana między innymi w aplikację klawiatury, dzięki czemu można włączyć nasłuch i nawet nie zauważyć.

Historię rozkazów wydanych mową można przejrzeć na stronie Google My Activity: Voice & Audio. Oferuje ona listę nagrań wraz z „rozpoznanymi” na nich wypowiedziami. Nie przypominam sobie, żebym kiedykolwiek korzystał np. z wyszukiwania głosowego, ale niniejsza strona zawiera dla mojego konta kilkaset próbek. Większość z nich to szum, urywki rozmów, których dawno już nie pamiętam, szelest telefonu wrzucanego do kieszeni i temu podobne. Są też ciekawsze artefakty: na przykład jedenastego czerwca 2016 wykrzyknąłem w stronę Google Now słowo „Mięso!”, z emfazą i niemal agresją w głosie. Co więcej! Uczyniłem to trzykrotnie. Historia zawiera trzy nagrania, każde brzmiące nieco inaczej. Nigdy nie dowiem się już, jakie były okoliczności skłaniające mnie do owego aktu. Choć może to i lepiej, że tego nie pamiętam.
WIDEO
Gdy zatem, korzystając z chat-bota kolejnej aplikacji do zamawiania pizzy chwyci nas tęsknota za dawnymi zamówieniami przez telefon i poczucie braku kontaktu z żywą istotą, pamiętajmy że być może po drugiej stronie znajduje się mały krasnoludek, który czyta to wszystko i podszywa się pod sztuczną inteligencję, abyśmy wszyscy mogli wmawiać sobie że żyjemy w przyszłości.

Administrator Windows Server i RHEL. Zajmuje się cyberbezpieczeństwem gdzieś w Fortune 500. Przejściowo nauczyciel akademicki. Wykazuje niezdrowe zainteresowanie filozofią, polityką i rujnowaniem rytmu dobowego. Jednordzeniowy.












