


Eksabajty danych w pudełku: Microsoft z syntetycznego DNA zrobił pamięć masową
W świecie, w którym modnym słowem staje się „eksabajt”, ana najpopularniejszy serwis wideo w Internecie wgrywa się bezzahamowań wideo 4K z zabawami kotków czy śmianiem się nastolatek,potrzeba lepszej pamięci masowej staje się coraz bardziej pilna. Wkońcu przez ostatnie kilka lat nie zmieniło się tak wiele,pojemność dysków twardych rośnie tylko liniowo, nie nadąża zailością produkowanej informacji. Potrzebujemy jakiejś rewolucji –i niewykluczone, że tę rewolucję przyniesie nam Microsoft.Naukowcy pracujący dla firmy z Redmond wzięli się zabiotechnologię, opracowującbardzo ciekawą metodę przechowywania danych w DNA. Na syntetycznejnici kwasu deoksyrybonukleinowego zapisali 200 MB, a następnieje odczytali. Może to niewiele, ale liczy się gęstość zapisu, ata wzrosła tysiąckrotnie w porównaniu do zapisu magnetycznego.


Zapis w materiale biologicznym w niczym nie przypomina zapisu„zer” i „jedynek” na elektronicznych czy magnetycznychnośnikach. W opracowanej przez badaczy Microsoftu i University ofWashington metodzie zera i jedynki są przekształcane w „litery”zasad azotowych nukleotydów (adenina, guanina, cytozyna i tymina –AGCT). Pozostający wciąż w elektronicznej formie zapis zostajenastępnie rozbity na części, z „liter” biolodzy molekularni zestartupu Twist Bioscencesyntetyzują wielką liczbę cząsteczek DNA, które wystarczyjedynie odwodnić, by zapewnić trwałość – możliwośćprzechowywania danych przez setki lat.
Microsoft and University of Washington DNA Storage Research Project
Odczytywanie tych danych wiąże się z wykorzystaniem reakcjiłańcuchowej polimerazy (PCR) do powielania łańcuchów DNA. Po tymjak znacząco zwiększona zostaje koncentracja pożądanychfragmentów, zostają one zsekwencjonowane i zdekodowane, a nawynikowym ciągu uruchamia się algorytmy korekcji błędów. W tenwłaśnie sposób zapisany został klip wideo OK Go pt. *This tooshall pass, *wraz znajpopularniejszymi książkami Projektu Gutenberg, PowszechnąDeklaracją Praw Człowieka w stu językach i bazą danych nasionorganizacji Crop Trust.
OK Go - This Too Shall Pass - Rube Goldberg Machine - Official Video
Sam Microsoft niewiele więcej ujawnił w komunikacie prasowym natemat zasady działania swojej pamięci DNA, ale znaleźliśmyartykuł,w którym działanie całego tego mechanizmu jest opisane znaczniebardziej rzetelnie.
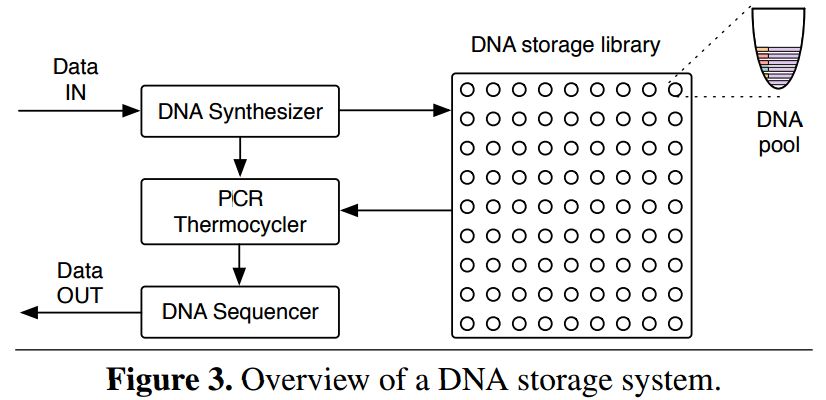
System pamięci masowej na bazie DNA wykorzystuje zautomatyzowanysyntetyzer DNA kodujący dane mające być przechowywane wcząsteczce, pojemnik-bibliotekę danych z przedziałamiprzechowującymi pule cząsteczek, oraz sekwencer DNA, któryodczytuje sekwencje kodu genetycznego i przekształca je w cyfrowedane.
Podstawową jednostką takiej pamięci jest nić DNA. Tworzy jąod 100 do 200 nukleotydów, może ona przechować od 50 do 100 bitówinformacji. Niewiele – a to oznacza, że zwykle obiekt informacjimusi zostać przeniesiony na wielką liczbę nici DNA. W tym celuwykorzystywana jest metoda adresowania klucz-wartość, w którejklucz jest powiązany z pulą zawierającą wymaganą nić, anastępnie mechanizm losowego dostępu służy do wydobycia nici zpuli.
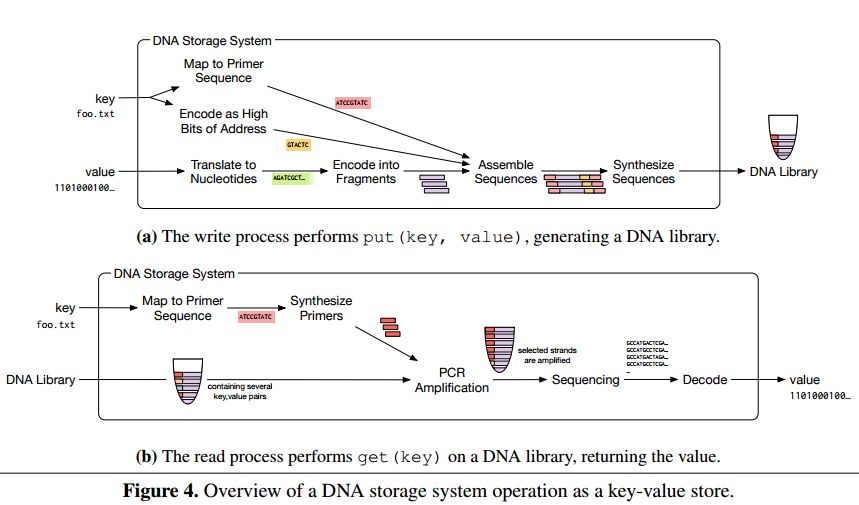
Mogłoby się wydawać, że konwersja z binarnych danych naczterozasadowy kod DNA zostanie zrobiona najprościej jak można,wykorzystując system liczbowy o podstawie 4. Np. bajt 011101112zapisalibyśmy jako 13134, czyli w kodzie genetycznym np.CTCT (cytozyna-tymina-cytozyna-tymina). Jednak badacze zdecydowalisię użyć systemu liczbowego o podstawie 3, tak by wykorzystywaćjeden nukleotyd na potrzeby korekcji błędów. Tak więc bajt011101112 zostaje zapisany jako 111023, czyliciąg CCCAG.
Ta korekcja błędów to kolejna poważna sprawa dla nośnikówDNA, poziom błędów jest tak wysoki, że wymaga oprócz popularnychalgorytmów ECC czy LDPC także redundancji, choć z możliwościąręcznego dostrajania, i to z dokładnością do bloku, w zależnościod poziomu dokładności wymaganego od przechowywanych danych.Wiadomo – są dane takie jak pliki JPG, w których pojedyncze błędynie stanowią problemu. Z drugiej strony kod maszynowy musi byćzapisany z pełną precyzją. Takie selektywne sterowaniedokładnością znacząco zwiększa też wydajność operacji zapisui odczytu – a operacje te wraz z rozmiarem danych stają się corazpowolniejsze i podatne na błędy.
Skoro już mowa o samej wydajności, to trzeba pamiętać ojednym: z DNA nie będzie zamienników dzisiejszych pamięcimasowych, ani dysków talerzowych, ani tym bardziej pamięcipółprzewodnikowych. Czasy dostępu są o rzędy wielkości wyższe,mierzone nawet w godzinach. Jednak w zamian dostajemy idealną pamięćarchiwalną, w której zapisane dane przetrwać mogą stulecia. Conajważniejsze zaś, jest to pamięć o ogromnej pojemności – jakto ładnie stwierdził jeden z badaczy, cały zbiór informacji natej planecie, szacowany na jakieś 700 eksabajtów, mógłby sięzmieścić w pudełku po butach. DNA bowiem doskonale się pakuje w trójwymiarowej przestrzeni.
Teraz, gdy naukowcy Microsoftu pokazali, że możliwy jest zapis iodczyt do biologicznych pamięci ze stuprocentową dokładnością,pozostaje tylko czekać na komercjalizację tego rozwiązania,właśnie jako nośnika pamięci archiwalnych. W końcu można chybapoczekać kilka minut na dostęp do rzadkiej książki czy filmusprzed stulecia.