







W jaki sposób komputer z sieci WAN może rozmawiać z "niewyNAT-owaną" usługą uruchomioną na komputerze w sieci WAN? Intuicja oraz "wiedza powszechna" podpowiadają, że to niemożliwe: routery podłączone do internetu dokonują translacji adresów dzięki której cała sieć lokalna jest widoczna w WAN-ie jako jeden komputer. Połączenia wychodzące działają dlatego, że router przekierowuje komunikację, której odbiorcą jest "sieć" do konkretnego komputera. Połączenia przychodzące nie działają, ponieważ de facto próbują nawiązać połączenie z portem routera, a nie docelowego komputera. Powstaje dzięki temu, przy okazji, "bieda-zapora": różnice adresacji i brak bezpośredniej trasy chronią komputery w LAN-ie przed nieupoważnionym dostępem.
NAT Slipstreaming
Kamkar przestawił wielokrokową metodę obejścia owej architektury. Proces zaczyna się od wyświetlenia przez ofiarę strony internetowej ze "złośliwym" kodem JavaScript. Zadaniem tej strony jest zidentyfikowanie prywatnego adresu IP komputera ofiary. Należy zaznaczyć, że znajomość samego takiego adresu nie ma samo w sobie szczególnej wartości. Dla przykładu, mój obecny adres to 10.0.0.103/20. Cóż z tego, skoro w każdej podsieci oznacza on coś innego?
O adres IP można... poprosić (odpowiedzi udzieli implementacja WebRTC w Chromium) lub można go wywęszyć: żądając załadowania zasobów wołanych z najpopularniejszych, prywatnych adresów IP. W praktyce polega to na dodaniu akcji "onerror" do obiektu img.
Fragmentacja TCP
Po ustaleniu prywatnego adresu, serwer atakującego i aplikacja strony internetowej załadowanej u ofiary dokonują wymiany bardzo dużych pakietów TCP i UDP wypełnionych ściółką (używam tego terminu, bo lubię być posądzany o korzystanie z translatorów). Duże pakiety wymuszają fragmentację, ta z kolei pozwala poznać szczegóły konfiguracji stosu TCP/IP u ofiary: dzięki niej da się określić np. MTU.
Wadliwe żądanie SIP
Następnie, aplikacja na stronie generuje samodzielnie składany pakiet inicjalizujący sesję SIP. To jest najciekawszy element układanki. Przeglądarki internetowe celowo blokują ruch na popularne porty usługowe, celem ochrony przed węszeniem w sieci. Nie blokują go jednak na port 5060, czyli port komunikacji SIP dla VoIP. Aplikacja w przeglądarce wysyła więc żądanie SIP do serwera atakującego na port 5060.
Ale jak? Przeglądarka jest przecież ograniczona w kwestii tego, jakie pakiety może wysyłać. Nie da się jej nieskończenie programować i dowolnie pisać po socketach w dowolną stronę (a przynajmniej nie bez poważnych ograniczeń). Dlatego "żądanie SIP" nie jest żadnym żądaniem SIP: to zwykła komunikacja HTTP POST, bo tak rozmawiają przeglądarki. Ale dzięki temu, że atakujący poznał sieciowe MTU i rozmiary pakietów, żądanie przybiera rozmiar wymuszający fragmentację. Dokonuje się ona w ściśle określonym miejscu pakietu.
Wymuszenie przekierowania
Sztuczne napompowanie pakietu i wymierzenie, jak system je łamie pozwala stworzyć taki pakiet, którego podział doprowadzi do "oczyszczenia go" z nagłówków HTTP. Stos sieciowy widzi ciąg pakietów i informację, że odbiorca ma je poskładać w jeden. Patrząc holistycznie, zbiór pakietów jest żądaniem HTTP POST. Ale patrząc "jeden-po-drugim", pierwszy pakiet, traktowany w oderwaniu od pozostałych, to poprawne żądanie SIP. Wszystko, co "HTTP-owe", ląduje w drugim.
Ta sztuczka sprawia, że routery wariują. Teoretycznie nie powinno to mieć dla nich znaczenia, bo to nie ich robota składać i rozdzielać pakiety. Tym ma się zająć odbiorca. Niestety jednak, żyjemy w piekle i obecne routery często są "smart": podsłuchują one przepuszczany przez siebie ruch w poszukiwaniu żądań SIP, połączeń BitTorrent, autokonfiguracji UPNP oraz tunelowania VPN. W przypadku wykrycia komunikacji o odpowiedniej specyfice, włączają "optymalizacje".
Efektem wykrycia komunikacji SIP jest... otwarcie przez usługę Application Layer Gateway na bramie (routerze) portu prowadzącego do portu komputera w WAN-ie. Router "myślał" bowiem, że następuje negocjacja połączenia VoIP między prywatnym komputerem a kimś w sieci. Zakłada zatem, że komputer oczekuje połączenia VoIP (przecież wysłał żądanie SIP!). Posłusznie przekierowuje więc otwarty port, umożliwiając komunikację między atakującym, a konkretnym portem na komputerze w LAN-ie.
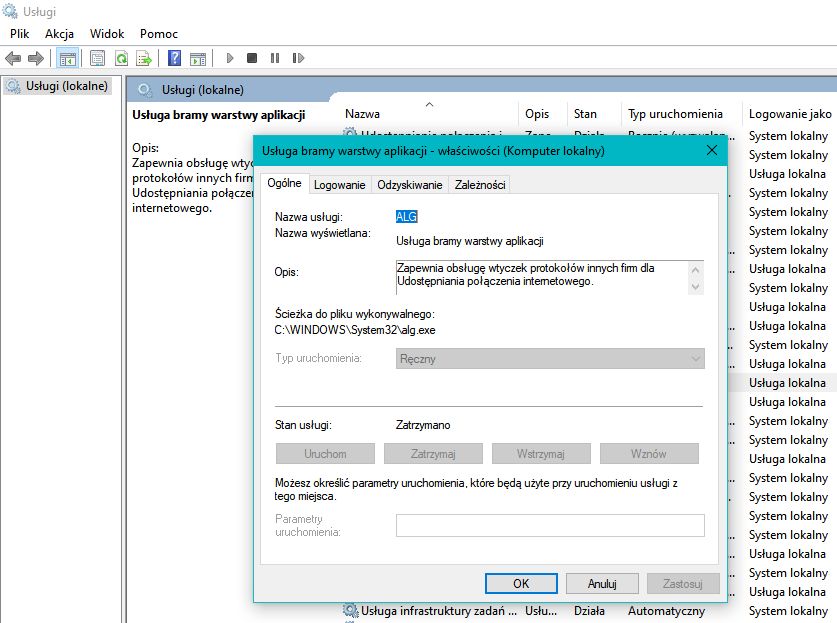
Nie takie wcale "smart"
Oczywiście, router podjął taką decyzję, ponieważ wcale nie jest "smart". Jest głupi jak but: znalazł w strumieniu komunikacji pakiet, który literalnie patrząc jest wezwaniem do telekonferencji, ale rozpatrywany w szerszym kontekście jest po prostu fragmentem nonsensownej (złośliwej) komunikacji HTTP POST, a więc czymś czego ma nie dotykać, jeżeli nie chce być posądzony o chałupnicze man-in-the-middle.
Można tu stwierdzić, że problemem jest błędna implementacja ALG. Z tym, że problem jest większy. ALG działa jak należy. Winny jest brak "kontekstowego ALG" czyli jakiejś super-skomplikowanej metody wykrywania czy ktoś się nie bawi fragmentacją pakietów. Być może i dałoby się ją zapewnić, ale będzie wtedy tylko kwestią czasu, gdy ktoś wymyśli jakiś meta-atak, który taką detekcję by oszukał.
Sprawdźcie ustawienia!
Rzeczywistym winnym są protokoły usiłujące wmówić nam, że trudne rzeczy da się robić w prosty sposób. Przezroczyste autokonfiguracje, wykrywanie usług, optymalizacja komunikacji i wszelkie inne pomysły zakładające, że router poprawnie zgadnie, co chcemy osiągnąć: ich istnienie w nieunikniony sposób wiąże się z powstawaniem przypadków brzegowych, podważających model bezpieczeństwa. Ethernet naprawdę powstał jako rozwiązanie na inne czasy.
Może warto rozważyć wyłączenie na routerze usług ALG i UPNP jeżeli się z nich w sieci nie korzysta...? Polecamy przynajmniej rozejrzeć się po panelu ustawień. No i zaktualizować firmware!

Administrator Windows Server i RHEL. Zajmuje się cyberbezpieczeństwem gdzieś w Fortune 500. Przejściowo nauczyciel akademicki. Wykazuje niezdrowe zainteresowanie filozofią, polityką i rujnowaniem rytmu dobowego. Jednordzeniowy.












