Problem stał się widoczny jakieś cztery lata temu, gdyrozpoczęły się prace nad usługą rozpoznawaniamowy w chmurze. Google zdało sobie sprawę, że gdyby wszyscyjego użytkownicy zechcieli skorzystać z tego systemu przez trzyminuty dziennie, to musiałoby podwoić liczbę wykorzystywanychcentrów danych, tylko po to, by obsłużyć obciążeniewykorzystywanych w nich systemów maszynowego uczenia się, wwiększości bazujących na akceleratorach GPU. Zamiast jednak braćsię do budowy nowych centrów danych, Google postanowiło spróbowaćsił w zaprojektowaniu czipu, którego architektura od podstaw będziezoptymalizowana pod kątem maszynowego uczenia.
Ostatecznie więc zdecydowano się na zbudowanie autorskiegoukładu ASIC, który pomoże wypełnić gwałtownie rosnące potrzebyw zakresie wykorzystania głębokich sieci neuronowych. Miał onzajmować się inferencją, czyli uruchamianiem już wytrenowanych naGPU sieci neuronowych, i ostatecznie otrzymał nazwę TensorProcessing Unit (TPU), jako że skrojono go pod kątem równoleglerozwijanego oprogramowania – biblioteki TensorFlow,przeznaczonej do obliczeń numerycznych z wykorzystaniem grafówskierowanych.

O konstrukcji TPU możemy się dziś dowiedzieć więcej zartykułuIn-Datacenter Performance Analysis of a Tensor Processing Unit,który właśnie został zgłoszony przez liczny zespół inżynierówGoogle’a na tegoroczne 44. międzynarodowe sympozjum architekturykomputerowej (ISCA). Pokrótce mówiąc, w TPU mamy macierz 65536 8-bitowychjednostek wykonywania operacji MAC (mnożenie-akumulacja), które podłączone są do dużej (28 MiB), software’owozarządzanej pamięci. Niczego specjalnego tam więcej nie ma, a choćcały układ to specjalizowany ASIC o ograniczonej liczbiewykonywanych instrukcji, Google twierdzi, że zachowało to pewnąelastyczność układów FPGA, tak by można było dostosować TPU doróżnych sieci neuronowych i różnych typów algorytmówmaszynowego uczenia się.
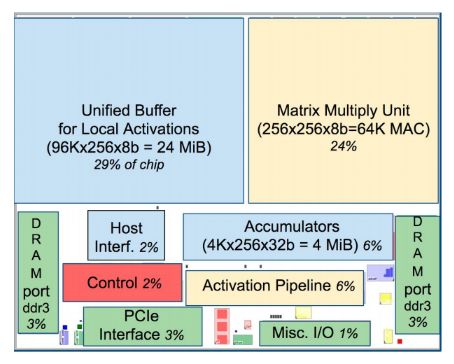
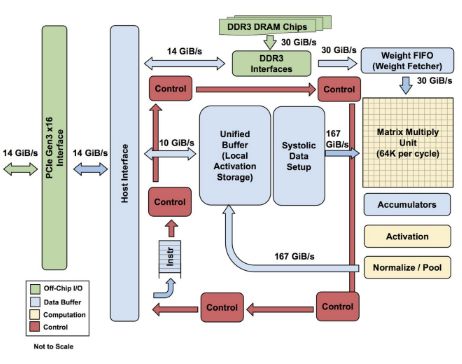
Dość interesujące jest to, jak TPU komunikuje się zkomputerem. Nie było czasu na integrację z procesorem, Googleposzło po linii najmniejszego oporu. Czip wpinany jest po prostu wmagistralę PCIe, w sumie tak samo, jak współczesne zewnętrznekarty graficzne. Jednak w przeciwieństwie do GPU samo nie pobierainstrukcji – to procesor musi wysłać mu rozkazy, co czyni gobardziej odpowiednikiem jednostki zmiennoprzecinkowej (FPU) niżprocesora graficznego.
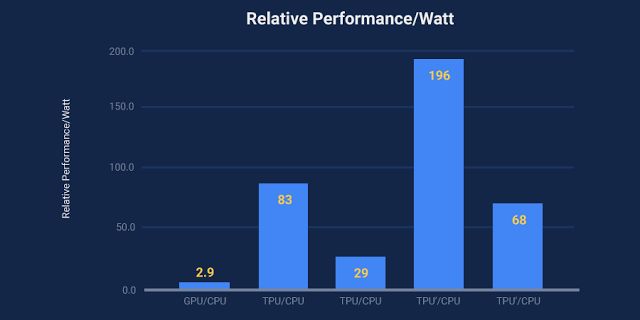
Najbardziej oczywiście interesujące są możliwości takiegoukładu. A te są oszałamiające, w praktyce czyniąc wykorzystanieCPU i GPU w uruchamianiu sieci neuronowych bezsensownymi. Googleprzedstawia dwie metryki, wydajność całkowitą na wat(uwzględniającą połączoną moc obliczeniową CPU i GPU lub TPU)oraz oraz wydajność przyrostową na wat (uwzględniającą jedyniemoc dostarczoną przez GPU lub TPU). Wszystko to w odniesieniu doprocesorów serwerowych Intela z rdzeniami Haswell oraz akceleratorówgraficznych Tesla K80 Nvidii. I tak oto:
- System z haswellowym CPU i akceleratorem Tesla K80, w stosunku dosystemu z samym CPU oferuje całkowitą wydajność na wat od 1,2 od2,1 razy większą. Wydajność przyrostowa Tesli K80 jest 1,7-2,9razy większa względem CPU z rdzeniami Haswella.
- Tymczasem system z haswellowym CPU i TPU w stosunku do systemu zsamym CPU oferuje całkowitą wydajność na wat od 17 do 34 razywiększą. Wydajność przyrostowa TPU jest zaś 41-83 razy większawzględem CPU i 25-29 razy większa od Tesli K80.
Warto podkreślić, że to dopiero pierwsza generacja TPU,zbudowana w litografii 28 nm, wykorzystywana w praktyce w centrachdanych Google’a od 2015 roku. Niebawem pojawi się druga generacja,wykorzystująca proces 14 nm, co powinno nawet dwukrotnie zwiększyćjej wydajność na wat.
Do tego dojdą ulepszenia logiki, mające przyspieszyć TPU onawet 50% oraz lepsza infrastruktura serwerowa. Można zastanowićsię nad szybszymi magistralami i szybszą pamięcią, które pozwoląnawet trzykrotnie zwiększyć wydajność tych jednostek tensorowych.
Na razie nie wiadomo w tej kwestii powie Nvidia. RozwiązaniaGoogle’a nie są na sprzedaż, przynajmniej nie bezpośrednio –Google chce, byśmy korzystali z nich przez upublicznione interfejsy.Czy ktoś rzuci rękawicę firmie z Mountain View, oferująckonkurencyjne architektury TPU, dostępne dla wszystkich na wolnymrynku? Jeśli nie, to w najbliższych latach Google osiągnieniemożliwą do wyrównania przewagę nad resztą świata wdziedzinie sztucznych inteligencji i maszynowego uczenia się.Pozostaje tylko czekać, aż mityczny Googlebot zastąpi cały zarządkorporacji, co by nie mówić potwornie ograniczony swoimi białkowymimózgami.