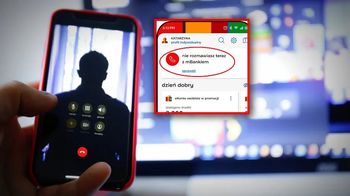




Inteligentne systemy zdolne do wyciągania wniosków z już przetworzonych informacji są jednym z ulubionych zagadnień założycieli firmy Google - Sergey'a Brina i Larry'ego Page'a. Zdaniem działu badawczego Google mogą one znaleźć zastosowanie w systemach tłumaczenia - gdzie poprawią jakość pracy translatorów - oraz w wyszukiwaniu informacji w liczących miliony bądź miliardy rekordów bazach. Korporacja przyznała, że prace nad systemami uczenia maszynowego trwają już kilka lat, a wszelkie działania w tym zakresie podejmowane są w ramach projektu o kryptonimie Seti.
Stworzony przez Google system samouczący jest tworem wysoce skalowalnym, jednak najlepiej sprawdza się w przetwarzaniu gigantycznych ilości informacji, w których zbiór sięga nawet 100 mld pozycji. Co ważne, system już po kilku minutach przetwarzania nowych danych jest w stanie wykorzystać je do poprawienia własnej efektywności. Dział badawczy stwierdził, że Seti może znaleźć zastosowanie wszędzie tam, gdzie uczenie maszynowe zapewnia znaczną poprawę osiąganych wyników w stosunku do istniejącego systemu.
Google zauważyło, że w nauczaniu maszynowym nie można za wszelką cenę stawiać na dokładność rezultatów, gdyż równie ważna w tego typu systemach jest łatwość obsługi, skalowalność i niezawodność. Jednak mimo, że prace nad Seti dają obiecujące rezultaty, nauczanie maszynowe nie jest niezawodnym panaceum na wszelkie problemy związane z przetwarzaniem ogromnych ilości danych. Wysiłek konieczny do integracji, utrzymania i obsługi systemu uczenia maszynowego może być czasem niewspółmierny do rezultatów - w niektórych miejscach lepiej sprawdzą się prostsze algorytmy.