




PathNet: Google pokazało, jak będzie działać ogólna sztuczna inteligencja
Marvin Minsky, pionier sztucznej inteligencji, zmarł w zeszłymroku. Nie zobaczył więc tego, o czym marzył całe życie –ogólnej sztucznej inteligencji, takiej, która jest w stanieprzenosić wyuczone umiejętności na inne dziedziny. Pierwszy realnykrok w stronę powstania takiej właśnie sztucznej inteligencjiprzedstawia dziś zespół Google Deep Mind. W artykule pt. PathNet:Evolution Channels Gradient Descent in Super Neural Networksopisane zostało działanie sieci utworzonej z sieci neuronowych,która jest w stanie transferować wyuczoną wiedzę.


Transfer umiejętności, czy też zjawisko przenoszenia wprawy,stanowi jedno z największych wyzwań dla AI. Chodzi o to, bysztuczna inteligencja ucząc się różnych dziedzin była w staniewykorzystać swoją dotychczas wyuczoną wiedzę w zupełnie nowychdziedzinach. Zakłada się, że będzie wówczas spisywała sięlepiej, niż zupełnie nowa sieć neuronowa.
Należący doGoogle’a startup DeepMind wsławił się już znaczącymiosiągnięciami. To jego badacze stworzyli siećneuronową z pamięcią i uwagą, to oni stworzyli pierwszegeneralizująceAI, uogólniające wyuczone aktywności, oni też przygotowaliAlphaGo,pierwsze AI, które pokonało najlepszego ludzkiego gracza go. Terazdemonstrują PathNet, sieć sieci neuronowych, która grając w jednąprostą grę na Atari, staje się coraz lepsza w innych grach.
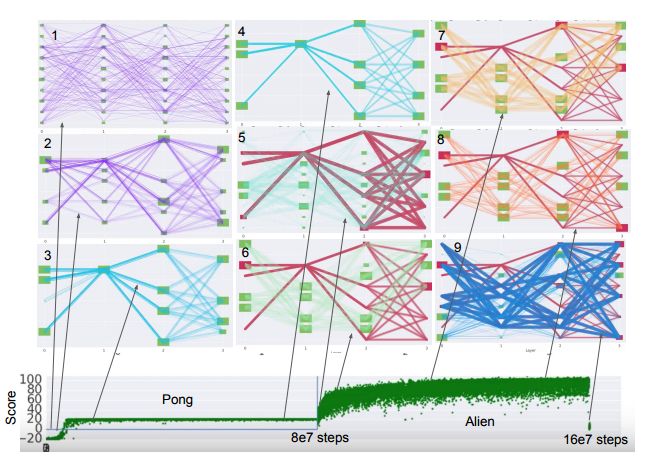
W skład PathNetu wchodzą różne sieci neuronowe – czy tojednokierunkowe, rekurencyjne, czy splotowe (konwolucyjne), trenowanezarówno metodą stochastycznego gradientu jak i genetycznejselekcji. Ułożone są one w warstwy modułów, a w tych modułachosadzone są agenty, których zadaniem jest odkrywanie, które częścisieci można wykorzystać do nowych zadań. Są to ścieżki przezsieć, określające podzbiór parametrów wykorzystywanych iprzekazywanych przez algorytm wstecznej propagacji.
Podczas uczenia się, algorytm genetyczny selekcji turniejowejwybiera ścieżki do replikacji i mutacji, uwzględniając ichgenetyczne fitness – mierzoną wydajność ścieżki. I jakwykazują autorzy pracy, ustalenie parametrów wzdłuż ścieżkiwyuczonej dla zadania A i wyewoluowanie z nich ścieżek dla zadaniaB pozwoliło wyuczyć się zadania B znacznie szybciej, niż robiłato sieć ucząca się od podstaw.
Jak działa takie szkolenie i transfer umiejętności? Mamyokreśloną liczbę warstw i modułów – zaprezentowany przezbadaczy przykład to układ 3×3. Po zdefiniowaniu tych modułów wsieci generowana jest określona liczba poddanych genetycznejselekcji ścieżek w sieci. Następnie wyzwalane są zadania(workers), używające asynchronicznego algorytmu AdvantageActor-Critic (A3C) do oceny każdej ścieżki – po wiele takichzadań na każdą.
Po określonej liczbie iteracji zadanie wybiera sobie ścieżki doporównania – i jeśli znajdzie ścieżkę o wyższym fitness, toprzyjmuje ją do dalszego szkolenia. Jeśli nie, to dalej poszukujeścieżek do porównania. Proces szkolenia ścieżki przeprowadzanyjest metodą gradientu stochastycznego ze wsteczną propagacją pojednej ścieżce naraz. Po wyuczeniu się zadania, sieć ustawiasobie parametry optymalnej ścieżki, nie modyfikując optymalnychścieżek wyuczonych dla poprzednich zadań.
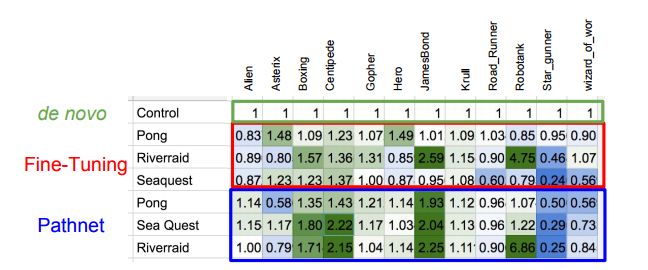
Z przedstawionych przykładów dla zestawu gier Atari możemyzobaczyć, że nie dla każdej pary gier transfer umiejętnościzadziałał, ale tak, gdzie się udało, wyniki są świetne. W parzeRobotank – Riverraid osiągnięto niemal siedmiokrotneprzyspieszenie względem świeżej sieci. Zdaniem autorów,przeniesienie tych metod na znacznie większe sieci, wykorzystywane wzadaniach w świecie rzeczywistym (np. sterowaniu ruchem robotów),przyniesie jeszcze lepsze efekty.
Warto zauważyć, że to co prezentuje PathNet dawno temustworzyła już ewolucja biologiczna – chodzi o takie specyficznepodkorowe struktury anatomiczne u ssaków, jądra podstawne. Toskupiska ciał komórek nerwowych bez wypustek, które wysyłająprojekcje do kory, wzgórza i pnia mózgu. Neurobiolodzy uważają,że odgrywają one kluczową rolę w procesach uczenia się,przetwarzaniu emocji i kontroli ruchowej organizmów. W pewnym sensiemożna więc powiedzieć, że zespół Google’a krok po krokutworzy sztuczny odpowiednik zaawansowanego organicznego mózgu,przewyższający jednak ten organiczny szybkością, skalowalnościąi łatwością replikacji.
Cały artykuł badaczy z DeepMind dostępny jest za darmo na arXiv.org
.












