Obliczenia równoległe: szansa i wyzwanie
Jak to działa? Framework zawiera specjalny, podobny do C język OpeCL99, który służy do tworzenia tzw. kerneli, czyli funkcji uruchamianych na urządzeniach, oraz interfejs programowania (API), dający kontrolę nad działaniem urządzeń. W uproszczeniu wygląda to następująco: host wysyła na urządzenia dane, polecenia do wykonania i pobiera wyliczone dane. Na hoście działa kod aplikacji pisany w normalnym C/C++ czy innym popularnym języku programowania. Na urządzeniach działa kod OpenCL, skompilowany za pomocą specjalizowanych kompilatorów, dostosowanych do specyfiki danego procesora.
To nie system operacyjny uruchamia kod OpenCL, lecz właśnie API tego frameworka, pozwalające na wykrycie urządzeń, określenie ich możliwości, skompilowanie programu dla nich, uruchomienie programu na wybranym urządzeniu, oraz wymianie informacji z hostem. Dzięki temu, jeśli np. program musi policzyć jakąś funkcję trygonometryczną dla macierzy liczb o rozmiarze tysiąc na tysiąc, to zamiast iterować po milionie liczb, OpenCL wyśle te dane na dostępne urządzenia, a następnie nakaże wykonanie funkcji dla każdej liczby w macierzy. Po ukończeniu operacji, zwróci dane do sterującego programu.
Jeśli jesteście zainteresowani szczegółami, to polecamy zacząć od prezentacji Aaftaba Munshiego, przygotowanej na konferencję SIGGRAPH.
OpenCL ma dwie fundamentalne zalety. Po pierwsze, potrafi wykorzystać możliwości procesora, bez względu na jego typ – właściwe optymalizacje zostaną użyte nie tylko dla różnych modeli CPU czy GPU, ale też FPGA czy DSP. Po drugie, stał się otwartym standardem dla heterogenicznego przetwarzania danych, ciesząc się wsparciem niemal całej branży: w dbającej o jego rozwój grupie Khronos znajdziemy takie tuzy jak AMD, ARM, Intel, NVIDIA, Samsung, Texas Instruments oraz oczywiście Apple.
W tym artykule chcemy Wam pokazać korzyści, jakie może przynieść zaprzęgnięcie do pracy GPU. Oprogramowanie, które wcześniej wykorzystywało tylko procesor główny, teraz staje się w niektórych zadaniach wielokrotnie wydajniejsze. Rola CPU w ten sposób nieco się kurczy. Ma to spore znaczenie przy wyborze nowego komputera. Może okazać się, że zamiast szukać jak najszybszego CPU, bardziej opłaci się kupić słabsze CPU i uzupełnić je mocniejszym GPU (albo dwoma), a w niektórych wypadkach, np. zainteresować się takimi rozwiązaniami jak APU od AMD, w jednym układzie przynoszące wydajne rdzenie GPU i (nie tak już wydajne) rdzenie CPU. Jest to szczególnie ciekawe w wypadku laptopów, gdzie nie mamy dużej swobody dobierania sprzętu – pozornie słabsza maszyna z APU Kaveri może się, dzięki OpenCL okazać w istotnych dla nas obciążeniach roboczych szybsza od Haswella.
Nasze eksperymenty
Możliwości OpenCL w praktyce przetestowaliśmy na dwóch laptopach.Pierwszy z nich to laptop red. Łukasza Tkacza, HP EliteBook 2570p zdwurdzeniowym procesorem Intel Core i5-3320M, ze zintegrowanymukładem graficznym HD 4000 i TDP na poziomie 35 W. Drugi to testowanyniedawno w naszym Labie HP EliteBook 755 GW z czterordzeniowymprocesorem AMD APU A10 Pro-7350B, zintegrowanym układem graficznymRadeon R6 i TDP na poziomie 19 W.
Syntetyczne benchmarki wydajności procesora nie dawały laptopowi z„czerwonym” procesorem zbyt wielkich szans. PrzykładowowPrime 2.0x uzyskał on wynik ok. 913 sekund, podczas gdy Intel byłniemal dwukrotnie szybszy, kończąc test w ciągu 536 sekund. WCinebenchu R10 wynik APU A10 (multiple CPU) to 7166 pkt, Core i5Intela uzyskało zaś 11700 pkt. Syntetyczne benchmarki niewiele jednakmają wspólnego z codziennym używaniem komputera. Postanowiliśmyzobaczyć, jak wygląda sytuacja, gdy do pracy zaprzęgniemy układgraficzny w APU, znacznie silniejszy przecież od tego, co znaleźćmożna w czipie Intela.
Na pierwszy ogień wzięliśmy nudne, biurowe sprawy – czyliarkusze kalkulacyjne. Od wersji 4.2 LibreOffice potrafi wykorzystaćOpenCL do przyspieszenia obliczeń. Niestety wciąż jest to domyślniewyłączone, a na dodatek dość ukryte. Obsługę OpenCL można włączyć wmenu Narzędzia, wybierając kolejno Opcje | Calc | Formuła |Szczegółowe ustawienia… | Niestandardowe. Wczytane zostałykolejno trzy testowe dokumenty w formacie Excela z pakietuOpenCL-test-documents.
Wyniki możecie zobaczyć na poniższych wykresach.
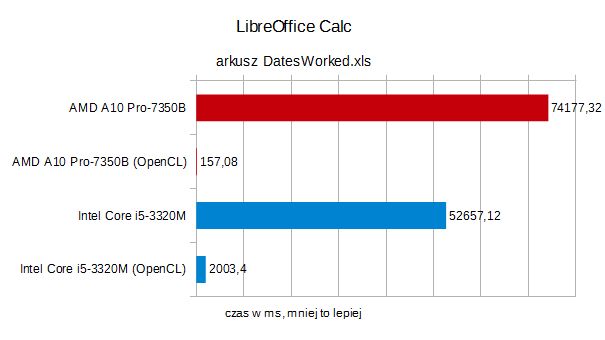
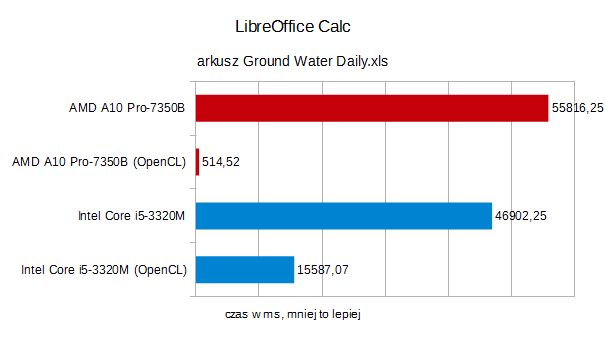
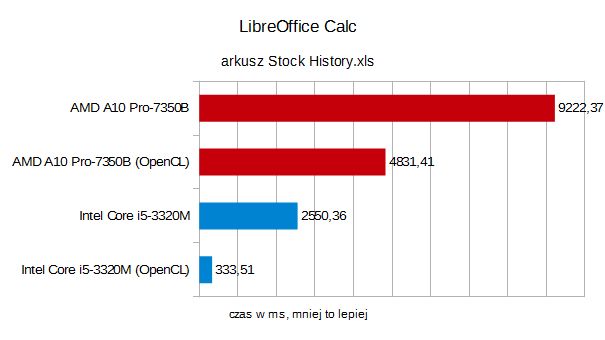
Jak widać, bez OpenCL, A10 było w każdym wypadku odczuwalniebardziej ślamazarne od mobilnego Core i5. Po włączeniu obsługiOpenCL, doszło do ogromnego, nawet kilkusetkrotnego przyspieszenia,procesor AMD nie dał intelowemu żadnych szans. W trzecim, gorzej sięparalelizującym arkuszu (Stock History), wygrał układ Intela, ale itu wynik A10 z OpenCL był niemal dwukrotnie lepszy.
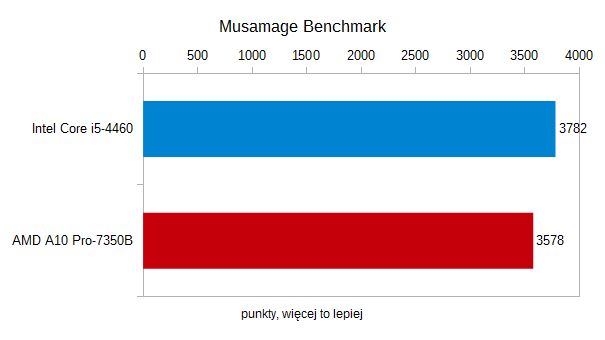
Następnie wykorzystaliśmy popularne narzędzie do edycji zdjęćMusemage– ma ono już wbudowany benchmark. Tu napotkaliśmy problem, gdyżedytor nie chciał się uruchomić na EliteBooku 2570p. Wykorzystaliśmywięc desktopową maszynę z czterordzeniowym procesorem Intel Corei5-4460. Trzeba zaznaczyć, że TDP tego procesora to 84 W, aporównujemy go do czipa użytego w laptopie. Jak widać, mimo tejróżnicy kategorii, laptopowy A10 z OpenCL nie miał się czegowstydzić, uzyskując wynik bliski desktopowemu Core i5.
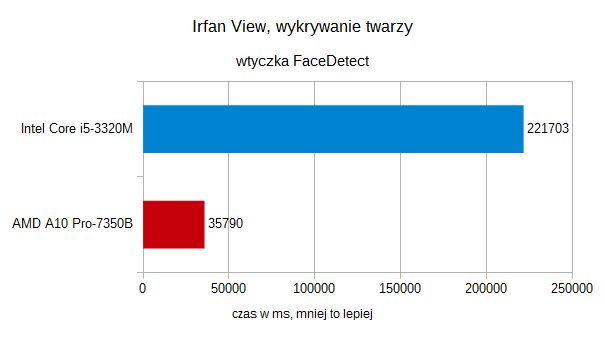
Kolejny test to również zadanie, które się dobrze paralelizuje.Wtyczka FaceDetectdla IrfanViewchętnie jest wykorzystywana przy demonstrowaniu możliwości OpenCL.Poniższy wykres wyjaśnia dlaczego, pokazując, jak wiele w dziedziniekomputerowego rozpoznawania obrazu może dać wydajne GPU.
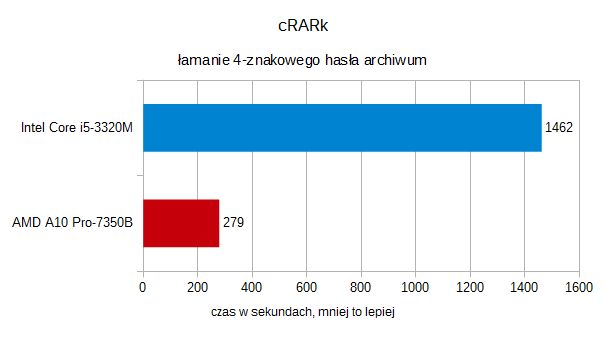
Niemniej przydatne GPU okazuje się przy łamaniu haseł. Prostenarzędzie cRARk do łamania hasełdo archiwów RAR potrafi wykorzystać OpenCL. Zabezpieczyliśmy archiwumz jednym zdjeciem 4-znakowym hasłem. APU okazało się tu pięciokrotnieszybsze od procesora Intela.
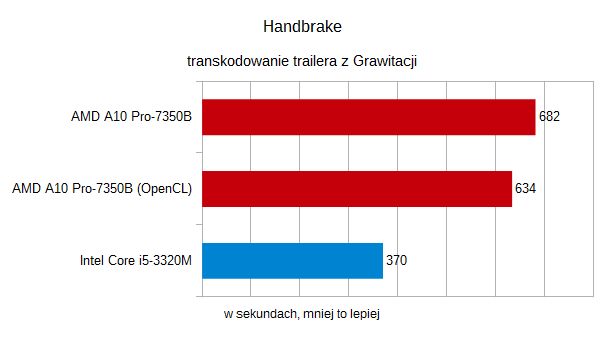
Nie ma co jednak popadać w hurraoptymizm. Są wypadki, w którychOpenCL w takim APU niewiele nam pomoże, a nawet może zaszkodzić.Przykładem może być transkodowanie wideo. Za pomocą narzędziaHandbrakespróbowaliśmy przekształcić zajawkę filmu „Grawitacja” zH.264 do Ogg Theory. Z OpenCL odnotowaliśmy niewielkie przyspieszeniedla APU, ale i tak procesor Intela okazał się sporo szybszy.
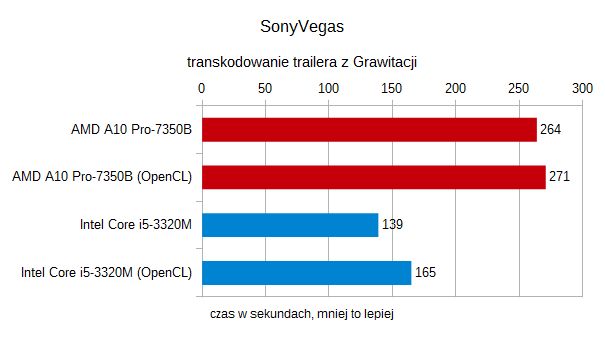
Jeszcze gorzej było z transkodowaniem tego samego klipu za pomocąSony Vegas. Duże obciążenie dla CPU i GPU sprawiło, że systempróbując utrzymać TDP na właściwym dla laptopa poziomie, dławiłzarówno procesory AMD jak i Intela – lepsze wyniki osiągnęliśmybez OpenCL.
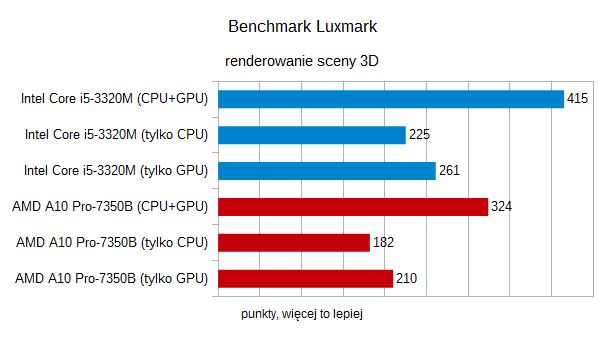
Finalnie sprawdziliśmy jeszcze renderowanie 3D, w benchmarkuLuxmark. Tu wydajność CPU okazała się znacznie istotniejsza odwydajności GPU, więc nawet z OpenCL w każdym wypadku układ Intelawygrywał.
Będzie trudniej, co nie znaczy gorzej
Uzyskane wyniki znacznie komplikują obraz sytuacji dla osób, którechciałyby kupić laptopa. Lista aplikacji obsługujących OpenCL stalesię wydłuża – są wśród nich zarówno proste, małe programiki,jak i potężne pakiety, takie jak Adobe CS6 czy Autodesk Maya. Sporeróżnice w architekturach Intela i AMD oznaczają, że wyniki testówtakich jak PCMark w wyborze nam nie pomogą, trzeba brać pod uwagękonkretne aplikacje z którymi pracujemy, te zastosowania, które sądla nas najważniejsze.
W wypadku desktopów (oraz najpotężniejszych laptopów z dyskretnągrafiką) dochodzi do tego kwestia, którą w tym artykule pominęliśmy,a mianowicie CUDA. Własnościowy framework CUDA od Nvidii (działającytylko na produktach tej firmy) jest w wielu wypadkach wydajniejszy odOpenCL – i choć nie jest oficjalnym standardem, to w szerokorozumianych dziedzinach inżynierskich jest powszechnie używany.Dodatkowo produkty Nvidii wspierają też OpenCL. Jeśli więc jużdecydujemy się na wykorzystanie karty graficznej do przyspieszeniapotrzebnego nam oprogramowania, to musimy zobaczyć, jak radzą sobietu GeForce, a jak Radeony.
Ogólny wniosek z tego jest jednak optymistyczny i to bez względuna to, z jakiego procesora czy systemu operacyjnego korzystamy.Paralelizacja okazała się owocną techniką i jest wspierana corazpowszechniej, sprawiając że te rdzenie GPU w naszych komputerachprzestają być tylko niepotrzebnym balastem, gdy akurat nie gramy wgry 3D. Kto wie, może kolejnym krokiem będzie pojawienie się wprocesorach ogólnego zastosowania jednostek programowalnych (FPGA)czy procesorów sygnałowych (DSP)?