







Całkiem sporo. Zastosowanie tak zdefiniowanego Unicode (są też inne!) sprawia, że każdy plik tekstowy efektywnie dwukrotnie rośnie. A ponieważ miejsce na dysku i szerokość łącz nie podwoją się tylko dlatego, że bardzo tego chcemy, natychmiast pojawiają się opory, czy na pewno "akurat teraz" jest konieczność zakodowania pliku w Unicode, bo wyjątkowo potrzeba nam dużo miejsca. Zadawanie takich pytań oznacza, że pomysł jest wadliwy. Wadliwość ta wynika nie z samego Unicode'u, ale z jego implementacji, np. UCS-2 (wszystko stanie się jasne już niedługo).
Skąd wiadomo, że znak jest szeroki?
Tych wad jest więcej. Przetwarzanie łańcuchów tekstu jest bardzo często operacją elementarną i nieabstrahowaną wyżej, celem zachowania wysokiej wydajności. Wskutek tego programy nierozumiejące, że nie mają już do czynienia z jednobajtowym tekstem, zaczynają wariować.
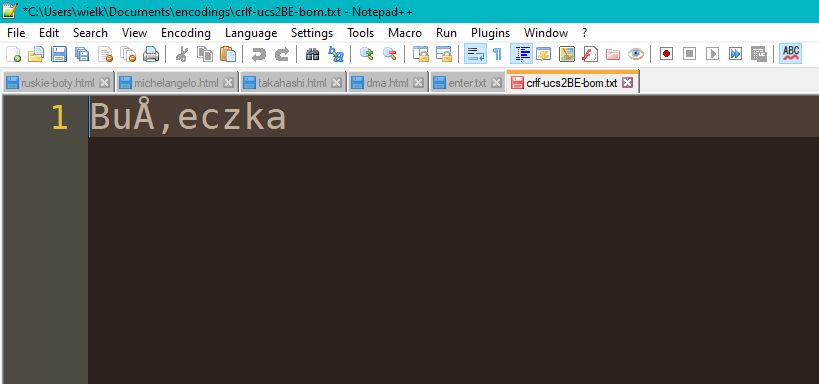
Kodowanie wielobajtowe o stałej szerokości zakłada, że jeżeli znak mieści się w tradycyjnym ASCII, nie zachodzi potrzeba wykorzystania drugiego bajtu i pozostaje on pusty (00). Gdy wielobajtowa litera ma jeden bajt pusty, wyświetlanie się nie posypie. Gdy jednak znak jest złożony (jak "ą" lub "🍉"), możemy dostać na ekranie śmieci, zależne w dodatku od strony kodowej, a więc różne między komputerami.
Jak stracić literki
Pal licho, gdy chodzi o samo wyświetlanie. Problem z programem nieświadomym tego, że ma do czynienia z wielobajtowym tekstem może prowadzić do utraty danych! Spójrzmy na poniższy prosty przykład w języku C. Osobom religijnie obrażonym wczorajszą pętlą for od razu ułatwię zadanie i podpowiem, że nie tak się parsuje pliki tekstowe, a deskryptor jest niebezpiecznie otwierany. Mając ten emfatyczny ceremoniał za sobą, popatrzmy:
#include "dobreprogramy.h"
char buf[24] ;
int main (void)
{
memset(buf, '\0', sizeof(buf));
int rb = read(open(UTFILE, 0x0000), buf, sizeof(buf)) ;
if (rb > 0) { printf("%s\n", buf) ; }
else { return rb ; }
// Proszę tak nigdy nie robić :)
}
Taki (prostacki) program, nakarmiony plikiem "tekstowym" o wielobajtowym zapisie, mimo pełnego bufora nie wypisze nic. Wewnętrzne struktury języka C sprawiają, że puste bajty pliku zakodowanego dwubajtowo są traktowane jako terminator i w konsekwencji program wypisuje pustkę. Mogłoby się wydawać, że to elementarny błąd i nie należy arbitralnie szastać printfem. Istotnie. Ale zarazem żyjemy w świecie, gdzie co chwilę trzeba gdzieś łatać przepełnienia bufora. Obrażanie się na kod nie wpływa na rzeczywistość, w jakiej funkcjonujemy.
Warstwa kompatybilności z piekłem
To jeszcze nie wszystko. Ponieważ, jak wiemy, przetwarzanie tekstu bywa niskopoziomowe i chodzi w nim o strumienie bajtów, alokowanie pamięci dla buforów również może odbywać się "niskopoziomowo" i w kolejności dyktowanej przez platformę. Tak się bowiem składa, że lokalizacja znaczącego bajtu między architekturami różni się. Na przykład x86 adresuje "od końca". Ta różnica przekłada się na miejsce dodatkowych bajtów dla znaków w tekście Unicode.
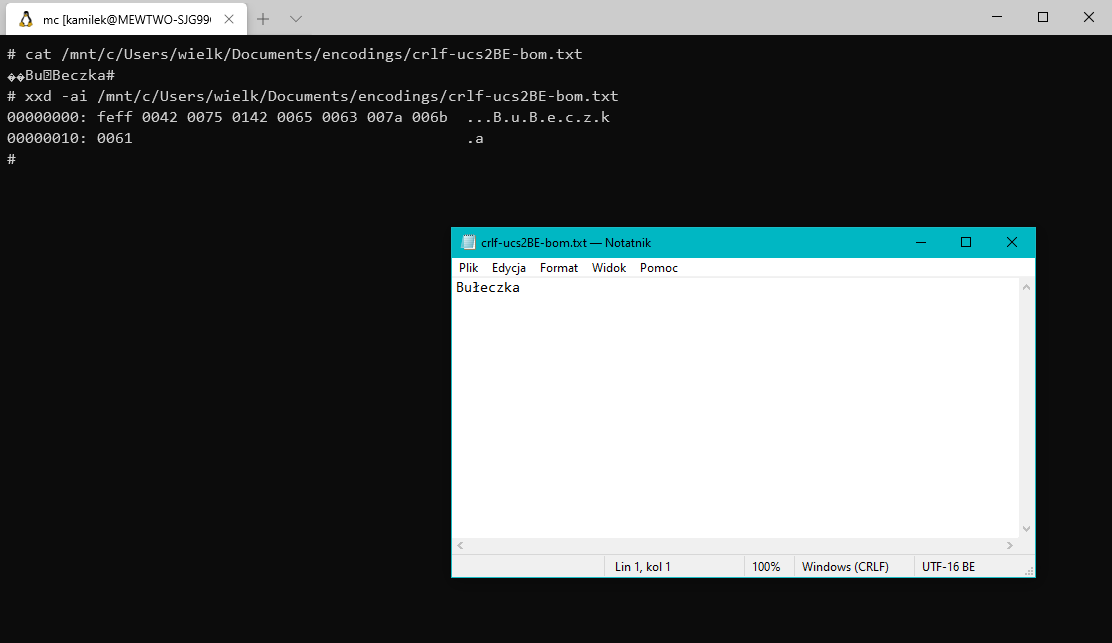
Jako, że i tak w tekst planujemy ładować dodatkowe bajty, co nam szkodzi do tekstu, na początku, dorzucić dwóch bajtów oznaczających porządek kodowania znaków? W ten sposób powstał Byte Order Mark (BOM), czyli dwa bajty: EE i EF. W zależności od ich ustawienia (EE EF lub EF EE) wiadomo, w którym kierunku liczy platforma i gdzie znajdują się znaczące bajty w strumieniu.
Co może pójść nie tak?
Oczywiście spontaniczne dodawanie bajtów do tekstu to dolewanie oliwy do ognia: próba rozwiązania stworzonego samodzielnie problemu poprzez pogarszanie sytuacji innym. Obecność BOM potrafi pięknie wyłożyć pliki skryptowe i wsadowe. Biedaskrypty BAT i CMD potrafią nie działać, gdy zaczynają się od BOM (acz nie zawsze...). Starsze wersje sh też potrafią się zaciąć na takich plikach, twierdząc np. że są binarne. Telnet rozłączy się, gdy napotka BOM, bo 0xFF jest ponad jego siły (IAC). Co gorsza, problem jest niewidoczny gołym okiem. Bajtów EE i EF nie widać w edytorze tekstu, więc łatwo je przeoczyć, chcąc rozwiązać problem nie znając jego źródła.
Jak sobie z tym poradzić? Krótko mówiąc - lepiej implementując standard Unicode! O zastosowanym rozwiązaniu dowiemy się z drugiej części.

Administrator Windows Server i RHEL. Zajmuje się cyberbezpieczeństwem gdzieś w Fortune 500. Przejściowo nauczyciel akademicki. Wykazuje niezdrowe zainteresowanie filozofią, polityką i rujnowaniem rytmu dobowego. Jednordzeniowy.












