







Podstawowy sposób zapisu tekstu to klasyczny strumień bajtów, w którym na jeden znak przypada jeden bajt (a na oznaczenie końca linii – dwa bajty). Ten najbardziej oczywisty sposób zapisu ma jednak pewną wadę. Jeden bajt pozwala zapisać jeden z 256 stanów i choć nasz alfabet jest krótszy, to nie jest jedynym alfabetem na świecie.
ASCII i strony kodowe
I tu zaczyna się problem: amerykański standard ASCII, używany w telegrafach, był nie tylko amerykański, ale i siedmiobitowy. Oznacza to zdefiniowanie jedynie podstawowego alfabetu bez adaptacji diakrytycznych oraz pozostawienie nieobsadzonych stanów dla "drugiej połowy bajtu" (siedem bitów to 128 stanów, czyli połowa bajtu).

Stanów tych nie dało się jakoś raz, a dobrze "dodefiniować", bo brakujących symboli jest o wiele więcej, niż wolnych 128 stanów. Dlatego powstał horror pod nazwą "strona kodowa": umowa opisująca jakie symbole są przyporządkowane pozostałym stanom. Sterownik wyświetlania (lub sam program) musiał załadować odpowiedni sterownik, by wyświetlić litery w odpowiedniej stronie kodowej.
Niejawne metadane
Dlatego niegdyś, przesyłając plik tekstowy, należało poinformować w jakiej stronie kodowej należy go wyświetlać, żeby nie ujrzeć "krzaków". Informacja ta, z oczywistych powodów, nie mogła zostać zawarta w samym tekście: musiałaby istnieć jako metadana pliku, a mało który z dawnych systemów plików obsługiwał metadane. Problem rozwiązywały niektóre lepiej przygotowane strony internetowe, które w swoich nagłówkach HTML META informowały o stosowanej stronie kodowej. Jeżeli program był odpowiednio nowoczesny i/lub grzeczny, rozumiał owe nagłówki i stosował się do nich.
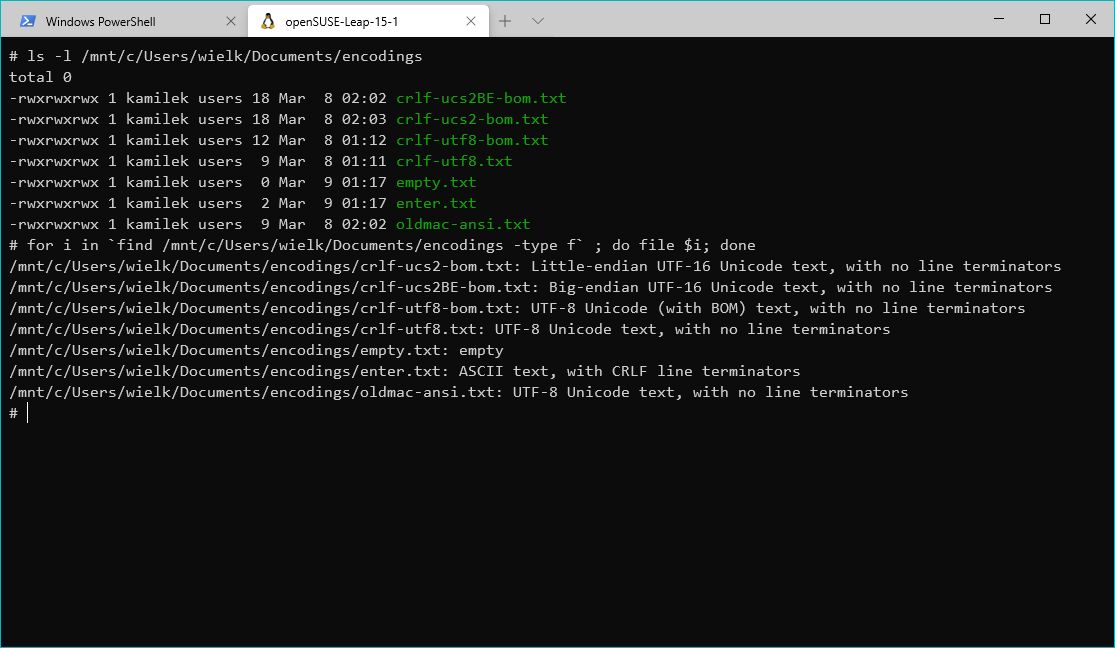
Nigdy jednak nie było tak, że każdy komputer u każdego oferował zbiór takich samych stron kodowych w takiej samej ilości. Często problem stanowiły same pliki czcionek, zdefiniowane na przykład tylko dla zachodnich stron kodowych (jak pierwsze wersje TTF czcionki Tahoma). Dlatego zasugerowano inne rozwiązanie: porzucić podejście jeden-bajt-na-jeden-znak. Ale uczynić to tak, by nie zerwać zgodności z ASCII.
Szerokie znaki
W ten sposób powstał Unicode, metoda zapisu tekstu, w której zastosowano podejście wielobajtowe. W ten sposób na każdy symbol przypadają (co najmniej) dwa bajty. W przypadku klasycznych znaków ASCII, te "dodatkowe bajty" są po prostu puste (00). Dzięki zastosowaniu dwóch bajtów na znak, skoczyliśmy z 256 dostępnych stanów do 65536. Na potrzeby tej części, "Unicode" będzie najpierw rozumiany tylko w ten sposób.
WIDEO
Ponieważ bajt 00 nigdy nie był literą, a symbole sterujące można zastosować, by rozszerzyć liczbę dostępnych stanów do wielu milionów, znika nam konieczność stosowania stron kodowych. Unicode jest ponadto standardem, co oznacza, że jest tylko jedna "strona kodowa" pilnująca przyporządkowania bajtu do symbolu. Jeżeli cały świat zacznie używać Unicode, problemy z kodowaniem znikną.
Czy zniknęły? Na to pytanie odpowiemy w kolejnej części.

Administrator Windows Server i RHEL. Zajmuje się cyberbezpieczeństwem gdzieś w Fortune 500. Przejściowo nauczyciel akademicki. Wykazuje niezdrowe zainteresowanie filozofią, polityką i rujnowaniem rytmu dobowego. Jednordzeniowy.












