





Rozwój polskiej sztucznej inteligencji nabiera tempa. Polski model AI - PLLuM przeszedł znaczącą aktualizację - poinformował Instytut NASK (czyli Naukowa i Akademicka Sieć Komputerowa - Państwowy Instytut Badawczy). Dzięki nowym danym i lepszym zabezpieczeniom, model jest teraz bardziej wszechstronny i odporny na ataki. Nowa wersja została opracowana na znacznie większym i lepiej przygotowanym zbiorze danych. Jest teraz dostępny w trzech wariantach, które można pobrać z platformy Hugging Face.
Trzy nowe wersje polskiego modelu językowego AI
Zaktualizowany model PLLuM jest dostępny w trzech wersjach: podstawowej, instrukcyjnej oraz zaawansowanej, która jest szczególnie zabezpieczona przed nadużyciami. Ta ostatnia wersja, oparta na ocenianych przez ludzi promptach, jest najbardziej rozwinięta i precyzyjna w reagowaniu na zapytania.
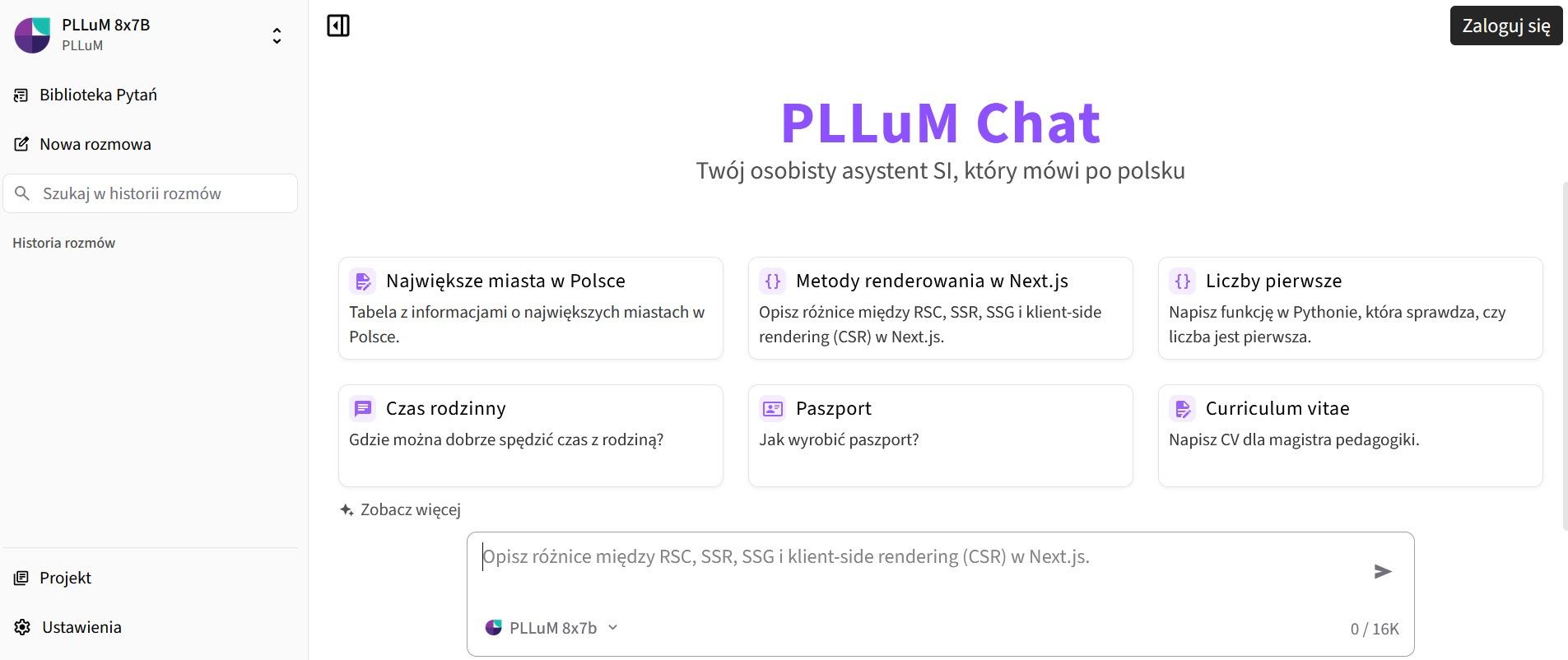
Model PLLuM-12B-nc-250715 powstał w trzech wariantach:
- base – to podstawowa wersja, która przeszła pełną adaptację językową na ogromnym polskojęzycznym zbiorze danych liczącym ok. 140 miliardów słów. To fundament, na którym zbudowano kolejne odsłony modelu.
- instruct – wariant instrukcyjny, dostrojony do realizacji szeregu zadań w języku polskim. Oznacza to, że został nauczony odpowiadać na pytania i realizować polecenia na podstawie par promptów i przykładowych odpowiedzi, co ułatwia mu lepsze rozumienie intencji użytkownika.
- chat – to najbardziej zaawansowana wersja, która przeszła dodatkowe "wychowanie". Oprócz adaptacji językowej i dostrajania na instrukcjach, została zabezpieczona i dostosowana do oczekiwań użytkowników. Oparto ją na zbiorach promptów oraz odpowiedzi ocenianych przez ludzi jako lepsze lub gorsze, co pomaga jej reagować bardziej precyzyjnie i bezpiecznie podczas rozmów.
Dalsza część artykułu pod materiałem wideo
Autorskie zbiory danych wyróżniają polski model PLLuM
Jak podkreślił NASK, nowy wariant PLLuM-12B-nc-250715 został wytrenowany na danych pochodzących z takich źródeł jak domena gov.pl, Biuletyn Informacji Publicznej oraz Biblioteka Nauki. Dr Agnieszka Karlińska z Zakładu Inżynierii Lingwistycznej i Analizy Tekstu NASK, kierowniczka projektu HIVE AI, zaznaczyła, że wszystkie dane są zbierane zgodnie z obowiązującymi przepisami prawa polskiego i europejskiego.

Dr hab. Piotr Pęzik, kierownik operacyjny projektu HIVE AI, podkreślił, że masowe kopiowanie gotowych modeli AI niesie ze sobą ryzyko, dlatego opracowano metodologię kontrolowanego generowania danych syntetycznych, które są weryfikowane przez ludzi. Dzięki temu model lepiej rozumie polski kontekst kulturowy i generuje bardziej precyzyjne odpowiedzi.
"Wyróżnikiem modeli PLLuM były zawsze autorskie zbiory danych do dostrajania modeli, czyli ich dostosowywania do określonych zadań. Pełna adaptacja językowa modeli jest możliwa tylko dzięki zbiorom mozolnie tworzonym od podstaw" - przekazał dr hab. Pęzik w komunikacie NASK.
Dodatkowo, model został zabezpieczony przed atakami promptowymi, co potwierdzają testy podatności, które wykazały zmniejszenie skuteczności takich ataków do 2-3 przypadków na 100 prób. Ataki te polegają na kierowaniu złośliwych instrukcji, które mogą prowadzić do generowania szkodliwych treści lub ujawniania poufnych informacji.
To nie jest ostatnie słowo twórców polskiego modelu AI
Dr Karlińska zapowiedziała, że konsorcjum HIVE wkrótce zaprezentuje kolejny produkt z rodziny PLLuM – prototyp asystenta obywatelskiego, który będzie pomocny w zbieraniu promptów do wdrożenia modeli PLLuM w aplikacji mObywatel. W najbliższych tygodniach mają zostać ogłoszone kolejne premiery konsorcjum HIVE AI.
Model PLLuM, który został stworzony z myślą o administracji, firmach, naukowcach oraz obywatelach, miał swoją premierę pod koniec lutego 2025 r. Ministerstwo Cyfryzacji ogłosiło wtedy powstanie konsorcjum HIVE AI, które skupia polskie ośrodki naukowe i instytucje cyfrowe, z NASK-PIB na czele, w celu opracowywania i wdrażania nowych polskojęzycznych modeli językowych PLLuM w administracji publicznej.