Poszło szybko – i znany transhumanista Ray Kurzweil, dyrektortechniczny Google'a, może tylko zacierać ręce. Kluczowa pracadotycząca technik głębokiego uczenia, A fast learning algorithmfor deep belief nets, opublikowanazostała raptem 10 lat temu. Kilka dni temu zaś system AlphaGopodczas drugiej gry z Lee Sedolem zaszokował praktycznie wszystkichobserwatorów, robiąc coś, co nie przyszłoby do głowy żadnemuczłowiekowi. 37. ruch, wyłożenie czarnego kamienia tak wybiło zrównowagi ludzkiego gracza, że wstał od stołu i wyszedł obmyćtwarz – a gdy wrócił, spędził dobry kwadrans zastanawiając sięnad kolejnym ruchem.
Ze słów komentatorów wynikało, że uważają to za błąd,pomyłkę oprogramowania, czymś co idzie wbrew całej tradycjiludzkiego go, gry mającej przecież już ponad 2500 lat. Jednak jużw kolejnych ruchach doceniono geniusz 37. ruchu – jeden z ekspertówmówił tylko: *to nie jest ludzki ruch, nigdy nie widziałem, byczłowiek zrobił takich ruch, to takie piękne, takie piękne… *
Wprowadzenie do gry Go
By zrozumieć problem, trzeba spojrzećna skalę problemu, jaki Go stanowiło dla badaczy sztucznejinteligencji. Wygrać z człowiekiem w szachy to dziś żadna sztuka,ludzcy arcymistrzowie nie mają już żadnych szans, a co dopierozwykli gracze. W każdym posunięciu tej strategicznej gry istniejeśrednio 35 możliwych rozwinięć, tymczasem w go średnio każdyruch przynosi 250 możliwych rozwinięć. Użycie siłowych metod,stosowanych w szachach (a mówią, że szachy to gra dla ludziinteligentnych) nie wchodzi w rachubę, użycie w go popularnychalgorytmów dla gier dwuosobowych, takich jak Alfa-beta, minimax,przechodzenie drzewa czy wyszukiwanie heurystyczne wiąże się zzastosowaniem niewyobrażalnej mocy obliczeniowej, długo jeszczeniedostępnej dla naszej cywilizacji.
Tak więc mimo tego, że odrozgromienia w meczu szachowym Garriego Kasparowa przez komputer IBMDeepBlue minęło już 19 lat, możliwości programów grających wGo były nikłe, co najwyżej grały one na poziomie doświadczonychamatorów (nawet mi, mimo że grywam w go bardzo sporadycznie, udałosię raz czy dwa z komputerem wygrać). Największym dotychczasosiągnięciem było pokonanie w 2013 roku przez program Crazy Stonejapońskiego mistrza Yoshio Ishidy, tyle że komputer miał tuhandicap czterech kamieni.

Zbudowane przez ludzi z kupionej przezGoogle firmy DeepMind oprogramowanie AlphaGo zmieniło drastyczniesytuację. W październiku zeszłego roku podczas swojego debiutupokonało bez handicapu europejskiego czempiona go, Fana Hui, wpięciu grach pięć do zera. Co szczególnie ważne, niewykorzystywało w tym jakiegoś niewyobrażalnego sprzętu. Testowanoje na klastrach obliczeniowych o różnej liczbie CPU i GPU –przeciwko Lee Sedolowi mecz rozegrano korzystając z wcale nienajbardziej rozbudowanej konfiguracji, z 1202 procesorami głównymi(Intel Xeon) i 176 procesorami graficznymi (karty Tesla Nvidii).
O tym jak działa AlphaGo,dowiedzieliśmy się jednak dopiero pod koniec stycznia, gdy w Natureopublikowano artykułpt. Mastering the game of Go with deep neural networks and treesearch. W uproszczeniu można powiedzieć, że ta sztucznainteligencja uczyła się trzyetapowym procesie. Pierwszym krokiembyło przeanalizowanie ok. 30 mln ruchów w grach rozgrywanych przezzawodowych ludzkich graczy na turniejach – w ten sposób AlphaGouczyło się, jakie ruchy są dobre, a jakie niekoniecznie, byopanować intuicyjny aspekt. To jest jednak podobne do ludzkiejnauki, w końcu gracze uczą się z rozgrywek innych, analizując ichsukcesy i porażki.
Drugi krok był jednak czymśniedostępnym już dla uwięzionych w czaszkach białkowych mózgów.AlphaGo zaczęło grać samo ze sobą, rozgrywając miliony gier zróżnymi instancjami nieco modyfikowanego oprogramowania, a pokażdej grze stawało się w go nieco lepsze. Krok finalny, związanyjuż bezpośrednio z dalekosiężnym planowaniem, związany był zpopularną heurystyką Monte-Carlo Tree Search, w której analizujesię najbardziej obiecujące ruchy, symulując rozwinięcia iwybierając te, w których rośnie prawdopodobieństwo wygranej.Rozrost drzewa wariantów ogranicza się poprzez losowe próbkowanieprzestrzeni poszukiwań (więcej o tej ciekawej metodzie możecieznaleźć w dobrymartykule na polskiej Wikipedii).
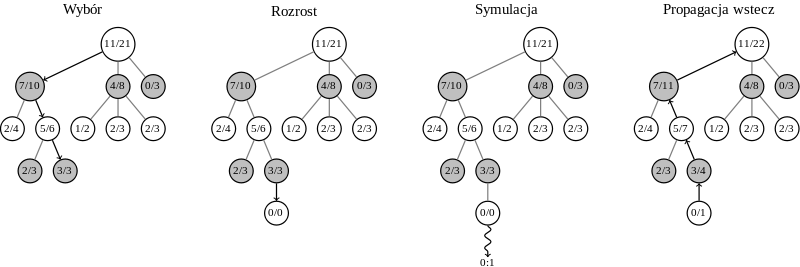
Tak wytrenowane AI, posiadające jużintuicyjną wiedzę o tym, jakie pozycje są dobre, wzięło się dogrania z innymi programami. W pięciuset meczach wygrało 499.Pokonanie Fana Hui było już tylko formalnością, mimo że jeszczew 2014 roku twierdzono, że pierwsze programy, które pokonająnajlepszych zawodowych graczy w go, pojawią się nie wcześniej niżw drugiej połowie przyszłej dekady. Nikt nie przewidział, jakskuteczne okaże się wzmacniane uczenie, w którym maszyny stająsię coraz lepsze, ucząc się na swoich własnych błędach.
Trwający wciąż mecz z Lee Sedolempokazał, że maszynowe umysły mogą nas naprawdę zaskoczyćinteligencją swoich działań. Pierwszego dnia, w wygranej przez AIgrze, wciąż można było sądzić, że to tylko przypadek, że Leenie docenił swojego przeciwnika i rozpoczynając śmiałym ieksperymentalnym dość otwarciem oddał zwycięstwo konserwatywnej wposunięciach maszynie, dając się uwikłać w taktyczną rozgrywkęo pojedyncze kamienie. W drugiej grze Lee grał wyraźnie lepiej,stawiając na sprawdzone, cierpliwe ruchy i czekając na błądmaszyny – tymczasem maszyna nie popełniła błędu, a zarazemzrobiła kilka genialnych ruchów. Trzeciego dnia to jednak byłamasakra. W opinii ekspertów AlphaGo grałolepiej, niż jakikolwiek ludzki gracz.
Choć mecz sztuczna inteligencja jużwygrała, pocieszyć fanów białkowej inteligencji może to, żekoreański gracz nie dał się psychicznie złamać i odniósł wrozegranej wczoraj czwartej grze zwycięstwo, w połowie rozgrywkiudało mu się zmusić maszynę do popełnienia błędu, z któregojuż nie zdołała się wydobyć. Twórcy AlphaGo bardzo się zezwycięstwa człowieka cieszą – pozwoliło im ono wykryć problem,który będą mogli usunąć. Ostatnia gra meczu już jutro, więctrzymajcie kciuki za Sedola, walczącego tu już tylko o dobre imięnaszego gatunku.
Lee Sedol wins game 4!!! Congratulations! He was too good for us today and pressured #AlphaGo into a mistake that it couldn’t recover from
— Demis Hassabis (@demishassabis) March 13, 2016Zbliżamy się jednak coraz bardziejwyraźnie do momentu, w którym i nasze możliwości umysłowe, zktórych jesteśmy tak dumni, zostaną niekorzystnie zweryfikowaneprzez coraz lepsze maszyny. Poprawiony AlphaGo już nigdy nie przegrameczu z człowiekiem, jego moc i doświadczenie może tylko rosnąć,podczas gdy Sedol nie zyska przecież więcej tkanki nerwowej. Możnaoczywiście się pocieszać, że to tylko gra planszowa, że ogólniewciąż jesteśmy lepsi – ale pamiętajmy, że chodzi o grę,której nie dało się wygrać zwykłą szybkością obliczeniową,że w Go wygrywa rozumienie sytuacji i intuicja, coś, na cowyłączność do tej pory miał ludzki intelekt. Lee Sedol możemoże oczywiście pocieszać się tym, że roboty nigdy niezrozumieją piękna gry w ten sam sposób jak my ludzie, ale coto za argument? Równie dobrze można powiedzieć, że my nigdy niezrozumiemy piękna gry w ten sam sposób jak AlphaGo.
Gry planszowe są więc „pozamiatane”.Twórcy AlphaGo chcą się teraz wziąć za gry 3D i symulacje, któremają o wiele więcej wspólnego ze światem rzeczywistym.Spodziewajcie się więc, że już niebawem sztuczne inteligencjezdominują turnieje e-sportowe. Co zostanie ludziom? Moim zdaniemnajdłużej opierać się maszynowej inteligencji będą grykarciane, takie jak Magic: The Gathering. Łącząc w sobie ogromnychrozmiarów drzewa decyzyjne, element losowości, ruchy zmieniającezasady gry oraz strategie optymalizacji talii wciąż są problemembardzo trudnym do ugryzienia. Ile czasu jakiemuś AlphaMTG zajmiewygranie z najlepszymi graczami na świecie? Cóż, sądzę, że jużdo końca tej dekady będziemy musieli uznać wyższość maszyn i wtej dziedzinie.
Wkraczamy więc w erę sztucznejinteligencji, dziarskim krokiem, ale pełni obaw. Coraz bardziejzaczynamy bowiem rozumieć, że scenariusze rodem z Terminatora sąnierealistyczne nie dlatego, że AI nie mogłoby by dążyć dozniszczenia ludzkości, lecz dlatego, że w słynnej serii sztucznainteligencja Skynetu jest przedstawiana jako bardzo… ludzka ibardzo ograniczona – jej motywy zrozumiałe dla nas, jej szybkośćreakcji i zdolności optymalizacyjne na poziomie tak zaniżonym, byludzcy protagoniści mieli jakieś szanse. Realne AI będą jednakdla nas niepojęte i niedościgłe, tak jak ruch 37. AlphaGo. Tymczasem zapraszam do kolejnego tygodnia z naszymportalem. Z interesujących tematów chcę zwrócić Waszą uwagę naodbywającą się dzisiaj debatę online w ramach akcji „Czytajlegalnie”, będącą próbą odpowiedzi na zjawisko piraceniae-booków. Przyjrzymy się też bliżej kwestiom związanym zsynchronizowaniem przeglądarek w czasach, gdy użytkownicykorzystają z wielu urządzeń jednocześnie, sprawdzimy najlepszeklawiatury ekranowe dla urządzeń z Androidem i zobaczymy, co możezrobić „zwykły Kowalski”, by zabezpieczyć swój router. Będzieteż coś dla miłośników Raspberry Pi i dobrego dźwięku:pokażemy, jak z odpowiednim osprzętem i oprogramowaniem z Malinyzrobić niezły sprzęt Hi-Fi. A na horyzoncie, co już mogęobiecać, ciekawy konkurs z atrakcyjnymi nagrodami.
Aktualizacja
AlphaGo wygrał po bardzo zaciętej walce piątą z gier w meczu z Lee Sedolem, wygrywając tym samym cały mecz 4:1. Warto podkreślić, że sztuczna inteligencja Google'a na początku ostatniej gry popełniła poważny błąd, ale później w fantastyczny sposób zdołała wybrnąć z sytuacji, przekuwając ją w swoje zwycięstwo.
#AlphaGo wins game 5! One of the most incredible games ever. To comeback from the initial big mistake against Lee Sedol was mind-blowing!!!
— Demis Hassabis (@demishassabis) March 15, 2016