Zespół DeepMind, należący do Alphabet Inc., ma na tym polu kolejne osiągnięcie. Jego nowa sztuczna inteligencja, nazwana AlphaZero, sama nauczyła się grać w trzy gry planszowe i ma na tym polu spore sukcesy. Pokonała innych komputerowych mistrzów w szachy, Go i szogi. AlphaZero jest ulepszoną wersją AlphaGo – sztucznej inteligencji, która została mistrzem Go.
Proces nauki AlphaZero odbywał się bez interwencji ludzi. Z artykułu podsumowującego doświadczenia możemy dowiedzieć się, że SI otrzymała jedynie zestaw podstawowych zasad każdej z gier. Grać w szachy uczyła się dziewięć godzin, w szogi dwanaście, a w Go 13 godzin. Wynik jest imponujący, ale należy odnieść go do odpowiedniej skali. AlphaZero wykorzystuje moc 5000 TPU (Tensor Processing Unit), a każda jednostka jest w stanie przetworzyć milion zdjęć z Google Photos w ciągu doby. Sukces uniwersalnej SI w kilku grach jest ważnym krokiem, ale bardzo też kosztownym.
Decyzję o kolejnym ruchu AlphaZero podejmuje z użyciem heurystyki Monte Carlo Search Tree (MCST), typowej dla znajdowania najlepszego ruchu w grach turowych, niedeterministycznych i grach czasu rzeczywistego.
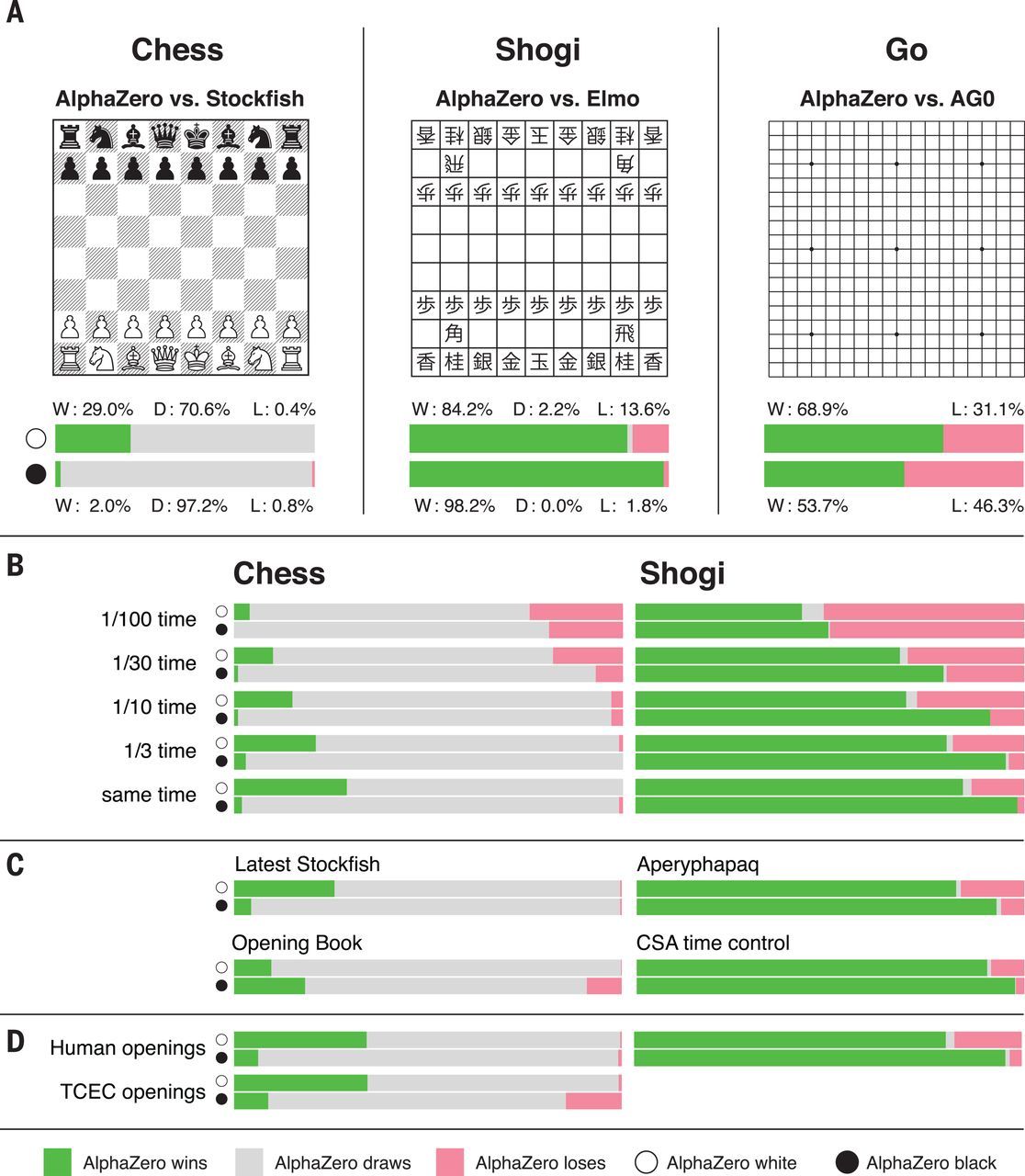
Następnie AlphaZero zmierzyła się z najlepszymi botami w każdej z dyscyplin. W szachy grała z programem StockFish, zbierającego najwyższe noty w rankingu CCRL. Na tysiąc rozegranych partii AlphaZero przegrała jedynie sześć, wygrała zaś 155. Pozostałe skończyły się remisem.
Szogi, czyli japońskie szachy, są grą trudniejszą od szachów, rozgrywaną na większej planszy i większym zestawem figur. AlphaZero już po dwóch godzinach treningu miała wyniki nieco lepsze do komputerowego mistrza z 2017 roku – programu elmo. Gdy po 9 godzinach treningu zmierzyła się z elmo, wygrała aż 91,2 proc. gier.
Najbardziej złożoną grą, jakiej uczyła się AlphaZero, jest Go. W tej wspaniałej konkurencji nowa SI zmierzyła się ze swoją starszą siostrą – AlphaGo. Młodszy i bardziej uniwersalny program zwyciężył w 61 proc. gier.
Na koniec warto dodać, że styl gry AlphaZero został pochwalony przez samego Garriego Kasparowa. Zauważył on, że programy szachowe zwykle dążą do perfekcji, wykonując ostrożne manewry, które zwykle prowadzą do remisu. AlphaZero potrafi zagrać agresywnie lub ryzykownie i przedkłada aktywność nad ochronę figur. W połączeniu z możliwością opanowania wielu gier czyni to z Alpha Zero solidną podstawę do opracowania uniwersalnego przeciwnika komputerowego.