







Osiągnięcie w postaci UTF-8 doprowadziło w pewnym sensie do klęski urodzaju. Gdy do kolejnych bloków Unicode wprowadzano m. in. całe glosariusze piktogramów matematycznych, końcowy zbiór znaków (dla porządku) zaczął obfitować w szereg symboli niezwykle podobnych do siebie. Z perspektywy kontekstu oraz mechanizmów składu tekstu, bywały to rzecz jasna zdecydowanie oddzielne symbole, ale dla niewprawnego oka wszelkie subtelności znajdowały się poza zakresem spostrzegawczości.
𝔡𝔬𝔟𝔯𝔢𝔭𝔯𝔬𝔤𝔯𝔞𝔪𝔶 𝖉𝖔𝖇𝖗𝖊𝖕𝖗𝖔𝖌𝖗𝖆𝖒𝖞 𝓭𝓸𝓫𝓻𝓮𝓹𝓻𝓸𝓰𝓻𝓪𝓶𝔂 𝒹𝑜𝒷𝓇𝑒𝓅𝓇𝑜𝑔𝓇𝒶𝓂𝓎 𝕕𝕠𝕓𝕣𝕖𝕡𝕣𝕠𝕘𝕣𝕒𝕞𝕪 dobreprogramy ᵈᵒᵇʳᵉᵖʳᵒᵍʳᵃᵐʸ 𝐝𝐨𝐛𝐫𝐞𝐩𝐫𝐨𝐠𝐫𝐚𝐦𝐲 𝘥𝘰𝘣𝘳𝘦𝘱𝘳𝘰𝘨𝘳𝘢𝘮𝘺 𝙙𝙤𝙗𝙧𝙚𝙥𝙧𝙤𝙜𝙧𝙖𝙢𝙮 𝚍𝚘𝚋𝚛𝚎𝚙𝚛𝚘𝚐𝚛𝚊𝚖𝚢
Ile alfabetów jest w alfabecie?
W ten sposób, litera R ma swoich mniej lub bardziej udanych sobowtórów wśród takich znaków, jak 𝐑 (Mathematical Bold Capital R, U+1D411), ᴿ (Modifier Letter Capital R, U+1D3F), 𝓡 (Mathematical Bold Script Capital R,U+1D4E1) i ℝ (Double-Struck Capital R, U+211D). Każdy z owych symboli jest oddalony od pozostałych o setki code pointów, ale wszystkie wyglądają łudząco podobnie, zwłaszcza po zastosowaniu odpowiednich adaptacji kroju. Mnogość liter o różnych krojach wynika teoretycznie z zapotrzebowania matematycznego na dystynktywne oznaczanie zbiorów i pojęć, ale zestawy znaków pogrubionych, pochyłych, pisanych i bezszeryfowych sprawiły, że za pomocą czystego UTF-8 można niemal formatować tekst.
𝐀𝐁𝐂𝐃𝐄𝐅𝐆𝐇𝐈𝐉𝐊𝐋𝐌𝐍𝐎𝐏𝐐𝐑𝐒𝐓𝐔𝐕𝐖𝐗𝐘𝐙𝐚𝐛𝐜𝐝𝐞𝐟𝐠𝐡𝐢𝐣𝐤𝐥𝐦𝐧𝐨𝐩𝐪𝐫𝐬𝐭𝐮𝐯𝐰𝐱𝐲𝐳𝐴𝐵𝐶𝐷𝐸𝐹𝐺𝐻𝐼𝐽𝐾𝐿𝑀𝑁𝑂𝑃𝑄𝑅𝑆𝑇𝑈𝑉𝑊𝑋𝑌𝑍𝑎𝑏𝑐𝑑𝑒𝑓𝑔𝑖𝑗𝑘𝑙𝑚𝑛𝑜𝑝𝑞𝑟𝑠𝑡𝑢𝑣𝑤𝑥𝑦𝑧𝑨𝑩𝑪𝑫𝑬𝑭𝑮𝑯𝑰𝑱𝑲𝑳𝑴𝑵𝑶𝑷𝑸𝑹𝑺𝑻𝑼𝑽𝑾𝑿𝒀𝒁𝒂𝒃𝒄𝒅𝒆𝒇𝒈𝒉𝒊𝒋𝒌𝒍𝒎𝒏𝒐𝒑𝒒𝒓𝒔𝒕𝒖𝒗𝒘𝒙𝒚𝒛𝒜𝒞𝒟𝒢𝒥𝒦𝒩𝒪𝒫𝒬𝒮𝒯𝒰𝒱𝒲𝒳𝒴𝒵𝒶𝒷𝒸𝒹𝒻𝒽𝒾𝒿𝓀𝓁𝓂𝓃𝓅𝓆𝓇𝓈𝓉𝓊𝓋𝓌𝓍𝓎𝓏𝓐𝓑𝓒𝓓𝓔𝓕𝓖𝓗𝓘𝓙𝓚𝓛𝓜𝓝𝓞𝓟𝓠𝓡𝓢𝓣𝓤𝓥𝓦𝓧𝓨𝓩𝓪𝓫𝓬𝓭𝓮𝓯𝓰𝓱𝓲𝓳𝓴𝓵𝓶𝓷𝓸𝓹𝓺𝓻𝓼𝓽𝓾𝓿
Wśród setek tysięcy znaków Unicode znajdują się również takie, które są nie tylko "raczej podobne" ale wręcz "niemal identyczne". Na przykład w przestrzeni klasycznych znaków CJK (Chinese-Japanese-Korean), przeznaczonej do przechowywania budulców dla symboli pełnej szerokości, kryje się cały podstawowy alfabet łaciński. Dość niewygładzony i nieco szerszy, ale w "maszynopisie" często nie do odróżnienia. Takie symbole nazywa się homografami (lub homoglifami): wyglądają tak samo, ale są różnymi znakami.
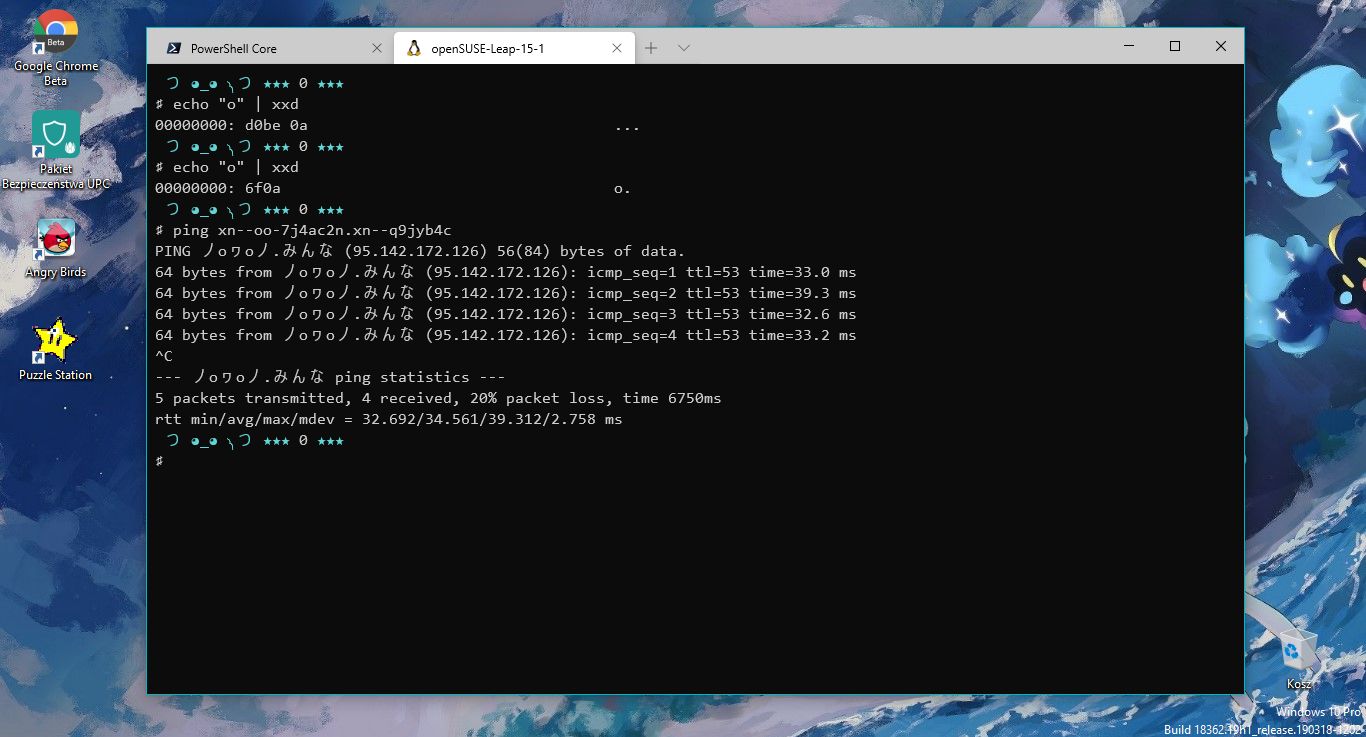
Międzynarodowy DNS
Stworzone w dobrej wierze i z uzasadnionych pobudek homografy zaczęły być używane w oszustwach. Głównym nośnikiem zła w tym temacie był mechanizm IDN w systemie nazw domenowych. Otóż od pewnego czasu obowiązuje standard, umożliwiający stosowanie w nazwach domen większości znaków Unicode (z wyłączeniem pewnych klas, jak interpunkcji). Domeny zawierające wielobajtowe znaki mogą być rozłożone do czystego ASCII za pomocą mechanizmu zwanego punycode. W przypadku większości ruchu, domeny są rozkładane do punycode "na wszelki wypadek".
Full Width: (っ◔◡◔)っ *✨:・゚✧【dobreprogramy】 ♡✿❀
Ale przeglądarki internetowe nie przyznają się do tego, wyświetlając na pasku adres ze złożonymi znakami. Linki do zasobów pod takimi adresami też zawierają wielobajtowe symbole zamiast rozłożonych, dziwacznych łańcuchów "xn--". Rozłożenie do ASCII adresów z emoji, alfabetem łacińskim i symbolami matematycznymi wcale nie musi sprawiać że będą one "działać". Standardy RFC to jedno, a konserwatywne implementacje – drugie. Nie tylko webowe formularze, ale też sporo drogiego sprzętu sieciowego, potrafi się wyłożyć na IDN. Jak łatwo zarejestrować taką "złowrogą" domenę i jakie są ich przykłady? O tym następnym razem.

Administrator Windows Server i RHEL. Zajmuje się cyberbezpieczeństwem gdzieś w Fortune 500. Przejściowo nauczyciel akademicki. Wykazuje niezdrowe zainteresowanie filozofią, polityką i rujnowaniem rytmu dobowego. Jednordzeniowy.












