

Nie ma czegoś takiego, jak czysty tekst. Najczęstsze problemy programistyczne
Wielobajtowe sposoby zapisu tekstu nie sprawiają wyłącznie problemów podczas ich czytania i wyświetlania. Rozwiązując problem kodowania znaków, wprowadzają przy okazji także szereg trudności programistycznych. Istnieje zwyczajowy zbiór problemów programistycznych związanych z Unicode, na które napotykają początkujący lub chwilowo nieostrożni deweloperzy. Niektóre z nich doprowadzają oprogramowanie do awarii, ujawniając się w sposób oczywisty. Inne z kolei potrafią trwać niezauważone przez długi czas, stanowiąc przy okazji potencjalne zagrożenie dla bezpieczeństwa.


Szerokość znaku i łańcuchy tekstowe
Gdy znajdujemy się w warstwach najniższego poziomu, kodowanie znaków teoretycznie nie ma znaczenia. Dla jądra systemu operacyjnego, zawartości pipe'ów komunikacyjnych, surowe strumienie pamięci i nazwy plików są po prostu ciągami bajtów. Nie ma znaczenia, w jaki sposób są kodowane. Problem zaczyna się nieco wyżej, gdy oprogramowanie musi zaimplementować obsługę złożonych znaków w językach ze świata C. Zmienna typu char wprowadza zamieszanie, ponieważ jeden char to jeden bajt, a jeden znak w UTF-8... nie zawsze. Stosowane bufory muszą też być odpowiednio większe, by pomieścić więcej bajtów na znak.
Co jednak w sytuacjach, gdy potrzebujemy zmiennej o długości kilku znaków, ale nie wiemy ile będą zajmować bajtów? Typ char odpada. Zamiast tego konieczne jest wyciągnięcie z wchar.h typu wchar_t, zdolnego do przechowywania znaków wielobajtowych. Naturalnie, maskuje to rzeczywiste użycie pamięci i wprowadza problemy własnego pochodzenia, ale jest lepsze od programów w C++ opartych o char, wykładających się na literce 'ą'.
Bajty NULL w standardzie UTF-16
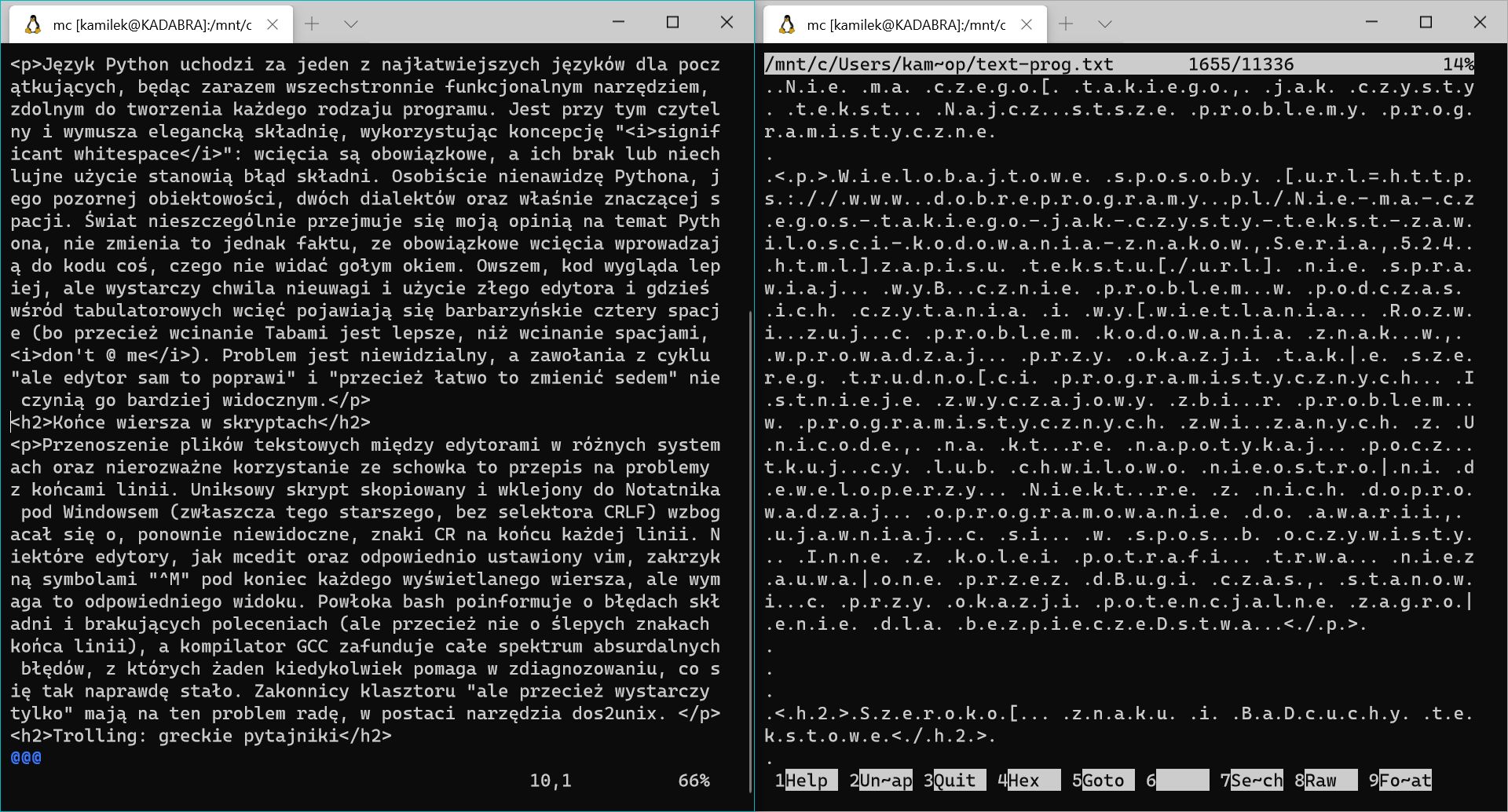
Uniksowe narzędzie grep może mieć problemy z przetwarzaniem plików tekstowych zapisanych w kodowaniu UTF-16. Wynika to z konsekwencji zastosowania w tym standardzie stałej szerokości znaku. W przypadku znaków, które nie potrzebują dodatkowego bajtu, jest on w nich ustawiany na 0x00. Ponieważ funkcje POSIX read() oraz write() operują na strumieniach bajtów, otworzą plik poprawnie, ale nic w nim nie znajdą, bowiem ta operacja działa już na znakach, a nie bajtach, a znaki są poprzeplatane NULL-ami. Wzorce wyszukiwania też musiałyby być poprzeplatane NULL-ami, a to stanowi trudność podczas... podawania ich jako argumenty wiersza poleceń. UNIX nienawidzi NULL-i i bardzo źle reaguje na puste bajty rozsypane w strumieniach.
Python i wcięcia
Język Python uchodzi za jeden z najłatwiejszych języków dla początkujących, będąc zarazem wszechstronnie funkcjonalnym narzędziem, zdolnym do tworzenia każdego rodzaju programu. Jest przy tym czytelny i wymusza elegancką składnię, wykorzystując koncepcję "significant whitespace": wcięcia są obowiązkowe, a ich brak lub niechlujne użycie stanowią błąd składni. Osobiście nienawidzę Pythona, jego pozornej obiektowości, dwóch dialektów oraz właśnie znaczącej spacji.
Świat nieszczególnie przejmuje się moją opinią na temat Pythona, nie zmienia to jednak faktu, ze obowiązkowe wcięcia wprowadzają do kodu coś, czego nie widać gołym okiem.Owszem, kod wygląda lepiej, ale wystarczy chwila nieuwagi i użycie złego edytora i gdzieś wśród tabulatorowych wcięć pojawiają się barbarzyńskie cztery spacje (bo przecież wcinanie Tabami jest lepsze, niż wcinanie spacjami, don't @ me). Problem jest niewidzialny, a zawołania z cyklu "ale edytor sam to poprawi" i "przecież łatwo to zmienić sedem" nie czynią go bardziej widocznym.
Końce wiersza w skryptach
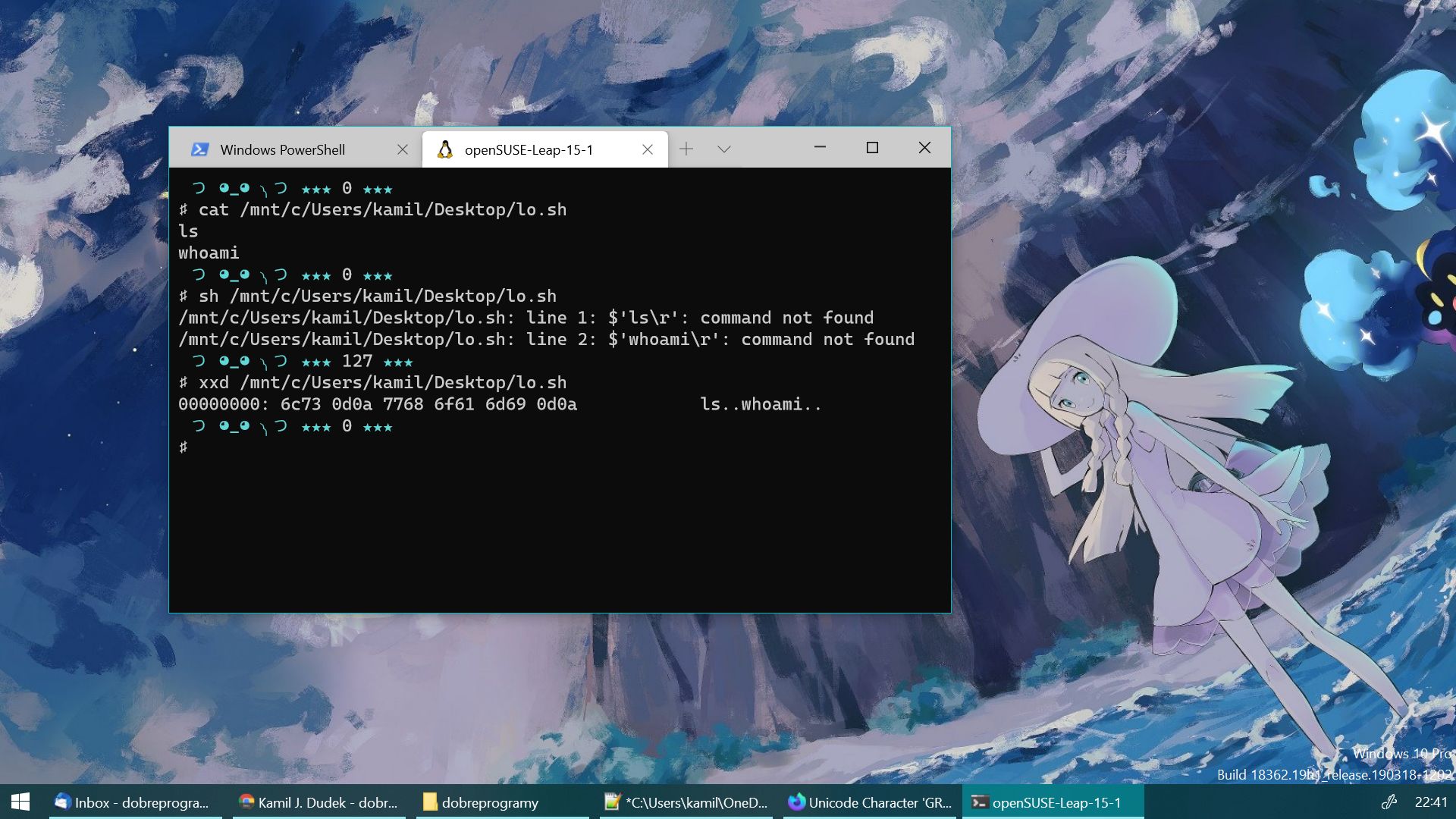
Przenoszenie plików tekstowych między edytorami w różnych systemach oraz nierozważne korzystanie ze schowka to przepis na problemy z końcami linii. Uniksowy skrypt skopiowany i wklejony do Notatnika pod Windowsem (zwłaszcza tego starszego, bez selektora CRLF) wzbogacał się o, ponownie niewidoczne, znaki CR na końcu każdej linii. Niektóre edytory, jak mcedit oraz odpowiednio ustawiony vim, zakrzykną symbolami "^M" pod koniec każdego wyświetlanego wiersza, ale wymaga to odpowiedniego widoku.
Powłoka bash poinformuje o błędach składni i brakujących poleceniach (ale przecież nie o ślepych znakach końca linii), a kompilator GCC zafunduje całe spektrum absurdalnych błędów, z których żaden kiedykolwiek pomaga w zdiagnozowaniu, co się tak naprawdę stało. Zakonnicy klasztoru "ale przecież wystarczy tylko" mają na ten problem radę, w postaci narzędzia dos2unix.
Trolling: greckie pytajniki
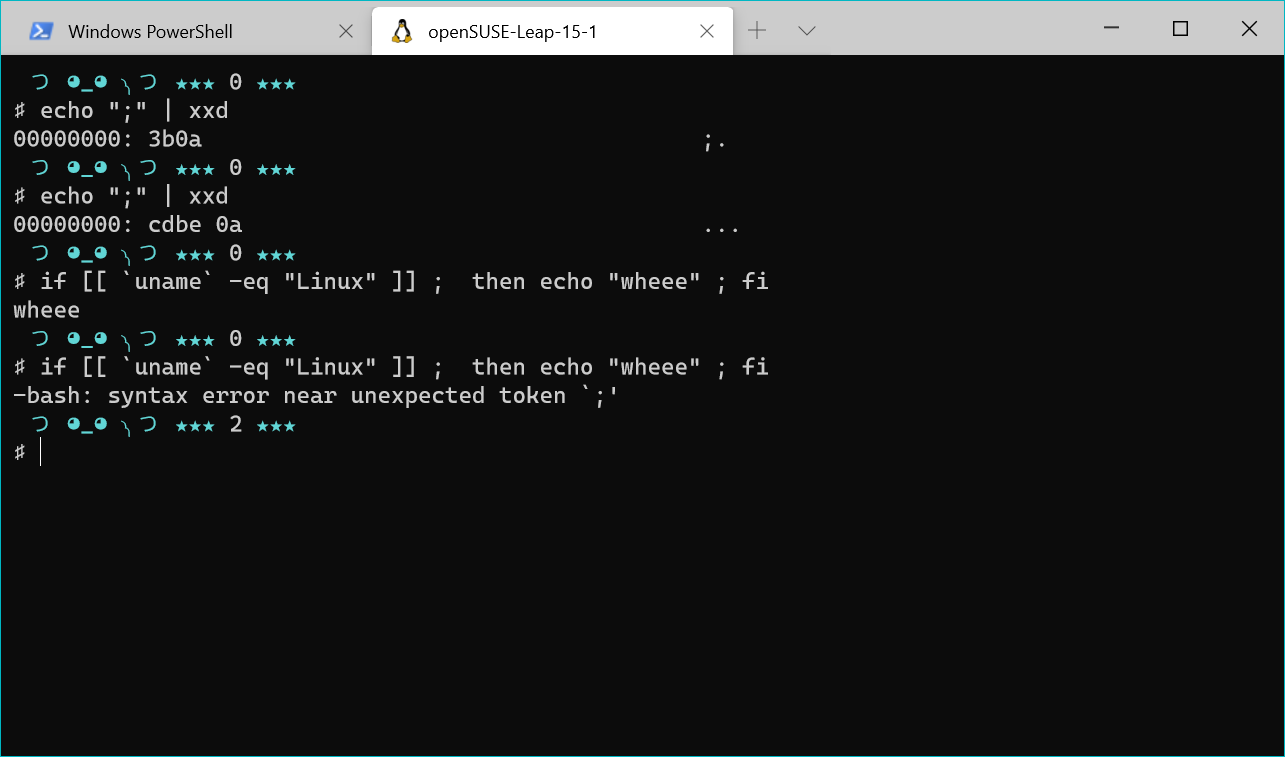
Jeżeli chce się zmęczyć programistę przeprawą z kodowaniem znaków, ale ma się do czynienia z osobą wprawną w kwestii wcięć, NULL-i oraz końców linii, można zastosować wariant nuklearny, w postaci zastąpienia średników w kodzie symbolem homograficznym greckiego pytajnika. Jak wygląda gracki pytajnik? Otóż tak: ;. Wraz ze średnikiem wyglądają identycznie. Ale radość serwowana przez nie, w postaci komunikatów "missing semicolon", jest bezcenna 😉