





Oprogramowanie OCR jest najczęściej dość drogie. Jeśli sporadycznie potrzebujemy odczytać tekst z plików graficznych, możemy skorzystać z darmowego Dysku Google. Wbudowana w niego funkcja OCR jest łatwa w obsłudze i działa bardzo sprawnie. Poniżej znajdziecie prosty przykład, jak z niej korzystać.
[quote]Darmowe oprogramowanie OCR? Wystarczy skorzystać z Dysku Google.[/quote]



Obsługiwane pliki
Dysk Google radzi sobie z rozpoznawaniem tekstu w pikach JPEG, PNG, GIF oraz PDF. Rozmiar pliku nie powinien przekraczać 2 MB. W przypadku skanów i zdjęć zwróćmy uwagę, by tekst był zorientowany poziomo (jak podczas czytania).
OCR od giganta wyszukiwarek automatycznie rozpoznaje język tekstu. Najlepsze efekty konwersji otrzymamy oczywiście, jeśli czcionka jest czytelna, a obraz ma dobrą jakość.
Odczytywanie tekstu z plików
Pierwszym krokiem jest oczywiście przesłanie na nasz Dysk wybranych plików. Następnie logujemy się na nasze konto I otwieramy Dysk Google w przeglądarce. Klikamy prawym przyciskiem na plik, który chcemy przekształcić do wersji edytowalnej i z części Otwórz w wybieramy opcję Dokumenty Google.
[img=ocr1]
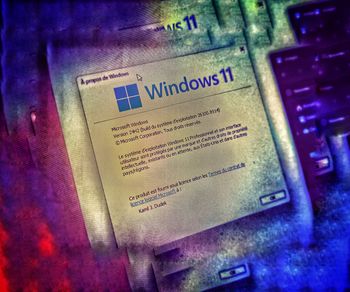
Po chwili dokument zostaje otwarty, a my możemy go dowolnie edytować. Pliki PDF otwierają się bezpośrednio w przetworzonej wersji.
[img=ocr2]
Zdjęcia i zeskanowane dokumenty różnią się tym, że oryginalny plik graficzny jest wklejany na początku dokumentu – pod nim znajduje się natomiast odczytany tekst.
[img=ocr3]
Przetworzone pliki są zapisywane jako oddzielne dokumenty na Dysku Google. Klienta usługi znajdziecie w naszej bazie oprogramowania.