







Udało się jednak rozwiązać ten problem. Ponieważ intuicyjne rozwiązania okazały się wadliwe i trudne, przyszedł czas na rozwiązanie nieintuicyjne. W ten sposób powstał standard UTF-8, osobliwe wykorzystanie kodowania wielobajtowego przy jednoczesnym zachowaniu zgodności z ASCII. Wiele osób twierdzi, że owa "zgodność z ASCII" oznacza istnienie w UTF-8 zbioru znaków kodowanych jednym bajtem, ale rzeczywistość wygląda nieco inaczej. UTF-8 stosuje zgodność z siedmiobitowym zapisem ASCII.
Dziwaczne rozwiązania prostych problemów
To jeden z wielu sposobów, na jakie standard UTF-8 jest nieintuicyjny. A przecież tylko pierwsze siedem bitów kodowania jest "bezdyskusyjne" i niezależne od stron kodowych! Ósmy bit, będący zawsze zerem w przypadku zakresu 0-127 pełni ważną rolę, informującą, że "reszta bajtu" jest zakodowana w ASCII. Każdy bajt tekstu UTF-8 zaczyna się od jedynki, poza bajtami kodującymi klasyczne ASCII. W ten prosty i genialny sposób zapewniono zgodność z czystym, amerykańskim tekstem, większością logów, kodami źródłowymi i tak dalej.
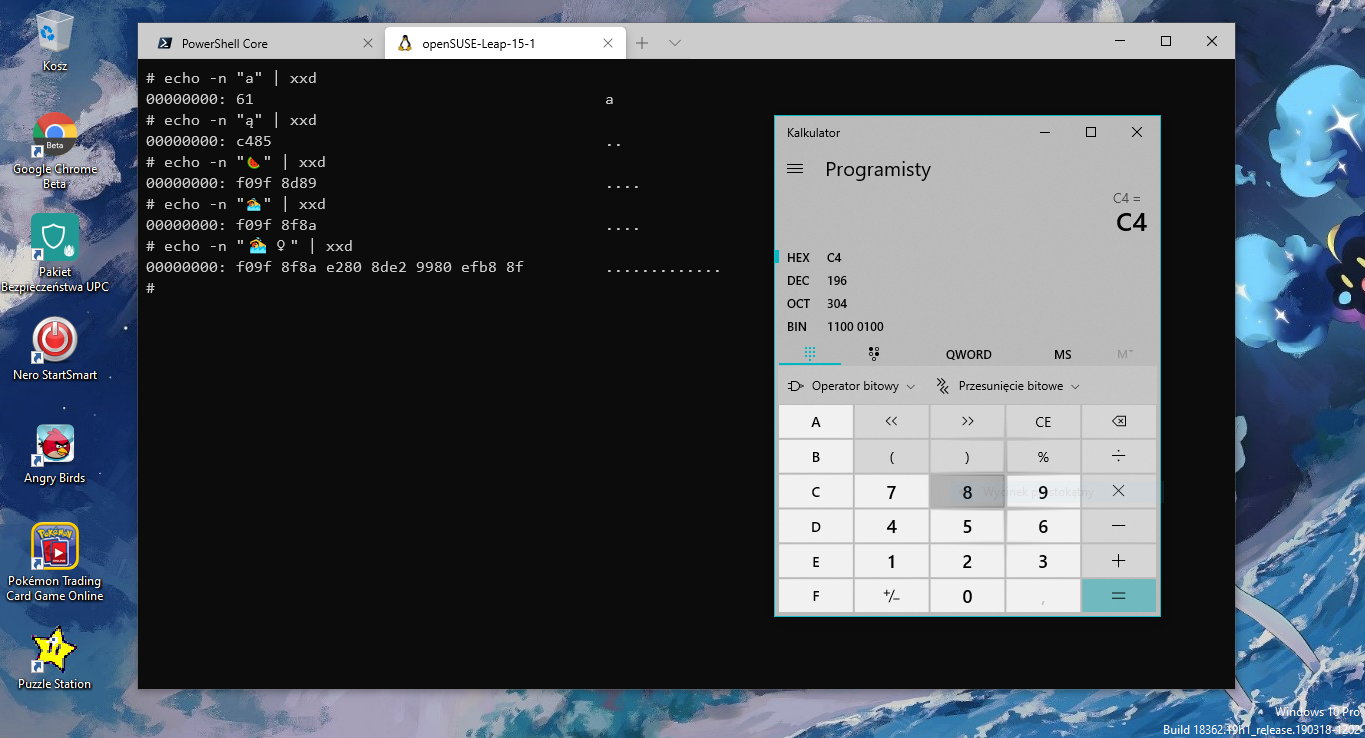
UTF-8 korzysta z unikodowego pojęcia o nazwie "code point", jednoznacznego identyfikatora symbolu. Każdy symbol ma swój numer zapisany szesnastkowo. Znaki ASCII stanowią wartości od 0 do 127, szesnastkowo 00 do 7F. W notacji Unicode identyfikatory tych znaków zapisuje się jako U+0000 do U+007F.
Reguły UTF-8
Wiemy już, że podstawowe znaki zapisuje się bajtem, którego najwyższy bit ma wartość 0. Jak zapisuje się bardziej skomplikowane znaki, wymagające wielu bajtów? Nieco szaleńczo, acz w szaleństwie jest metoda. Na początek należy wyartykułować wprost, że skoro podstawowe znaki zaczynają się od zera, to żaden inny bajt w Unicode, nawet będący składową innej litery, nie będzie się tak zaczynać. Wiedząc to, łatwiej da się zrozumieć reguły wielobajtowego kodowania. A są one następujące:
- Kolejność bajtów (endianness) jest ustalona. Pierwszy od lewej jest definiujący, pozostałe są dopełniające.
- Pierwszy bajt zaczyna się od jedynek w ilości odzwierciedlającej z ilu bajtów składa się znak, a następnie z zera.
- Drugi i każdy kolejny bajt zaczyna się od jedynki i zera. Dzięki temu wiadomo, że nie jest pierwszy i że nie koduje jednobajtowego znaku ASCII
I tyle. Oznacza to, że każdy znak UTF-8, jeżeli nie jest podstawowym znakiem ASCII, składa się z bajtu sterującego oraz jednego lub większej ilości bajtów pomocniczych, efektywnie kodujących po sześć bitów (sześć, a nie osiem, bo początek to zawsze 10). Odpada niezgodność z ASCII, odpada dwukrotne spuchnięcie tekstu, odpadają problemy z kolejnością bajtów i nie ma żadnych dodatkowych symboli kontrolnych, jak ten nieszczęsny BOM na początku pliku.
Standard de facto
W dodatku, gdy edytor tekstu nie rozumie UTF-8, uszkodzeniu ulegną tylko "szerokie" symbole, interpretowane na siłę jako kilka znaków, a nie jeden. To znacznie lepszy scenariusz niż zasypanie całego tekstu NULLami co każdą literkę.

Dwa tygodnie temu wydano wersję 13.0 standardu Unicode. Zawiera on obecnie niemal wszystkie znane alfabety oraz niezliczone piktogramy i Emoji. Da się oczywiście znaleźć twory ludzkiej kultury, których brak w Unicode, np. alfabet Voynicha lub rongorongo, obecne bogactwo Unicode'u sprawia, że problemem może być bardziej brak odpowiedniej czcionki w systemie, niż brak symbolu. A standard UTF-8 ubezpieczył nas nieco na przyszłość. Milion znaków to wbrew pozorom bardzo dużo.

Administrator Windows Server i RHEL. Zajmuje się cyberbezpieczeństwem gdzieś w Fortune 500. Przejściowo nauczyciel akademicki. Wykazuje niezdrowe zainteresowanie filozofią, polityką i rujnowaniem rytmu dobowego. Jednordzeniowy.












