





Siri: Star Trek Computer
Latem tego roku producent Firefoksa zwrócił się do internetowejspołeczności z prośbą o nagrywanie próbek mowy (w językuangielskim), jak również o przeglądanie maszynowej transkrypcjipróbek wypowiedzi innych. Do projektu o nazwie Common Voiceprzystąpiło niemal 20 tysięcy osób, którzy nagrali ponad 400tysięcy próbek – łącznie około 500 godzin nagrań, 12gigabajtów danych.
Ten ogromny zbiór został teraz udostępniony za darmo, na wolnejlicencji dla każdego zainteresowanego. Pobrać go możecie ze stronyvoice.mozilla.org/data,gdzie znajdziecie jeszcze linki do innych wolnych zbiorów nagrańludzkiej mowy. Jest to wartościowy dar dla wszystkich niezależnychprogramistów i startupów, gdyż porównywalne komercyjne zbiorysprzedawane są za dziesiątki tysięcy dolarów.
Mając taki zbiór można startować z pracą nad interfejsamigłosowymi – póki co po angielsku. Na angielskim oczywiście światsię nie kończy, Mozilla zdaje sobie z tego sprawę. Sean White zMozilli zapewnia, że już w pierwszej połowie przyszłego rokurozpocznie się praca nad rozszerzeniem Common Voice o inne języki.To, jak oprogramowanie w przyszłości będzie sobie radziło zprzetwarzaniem polskiej mowy zależy więc też od Was, drodzyCzytelnicy.
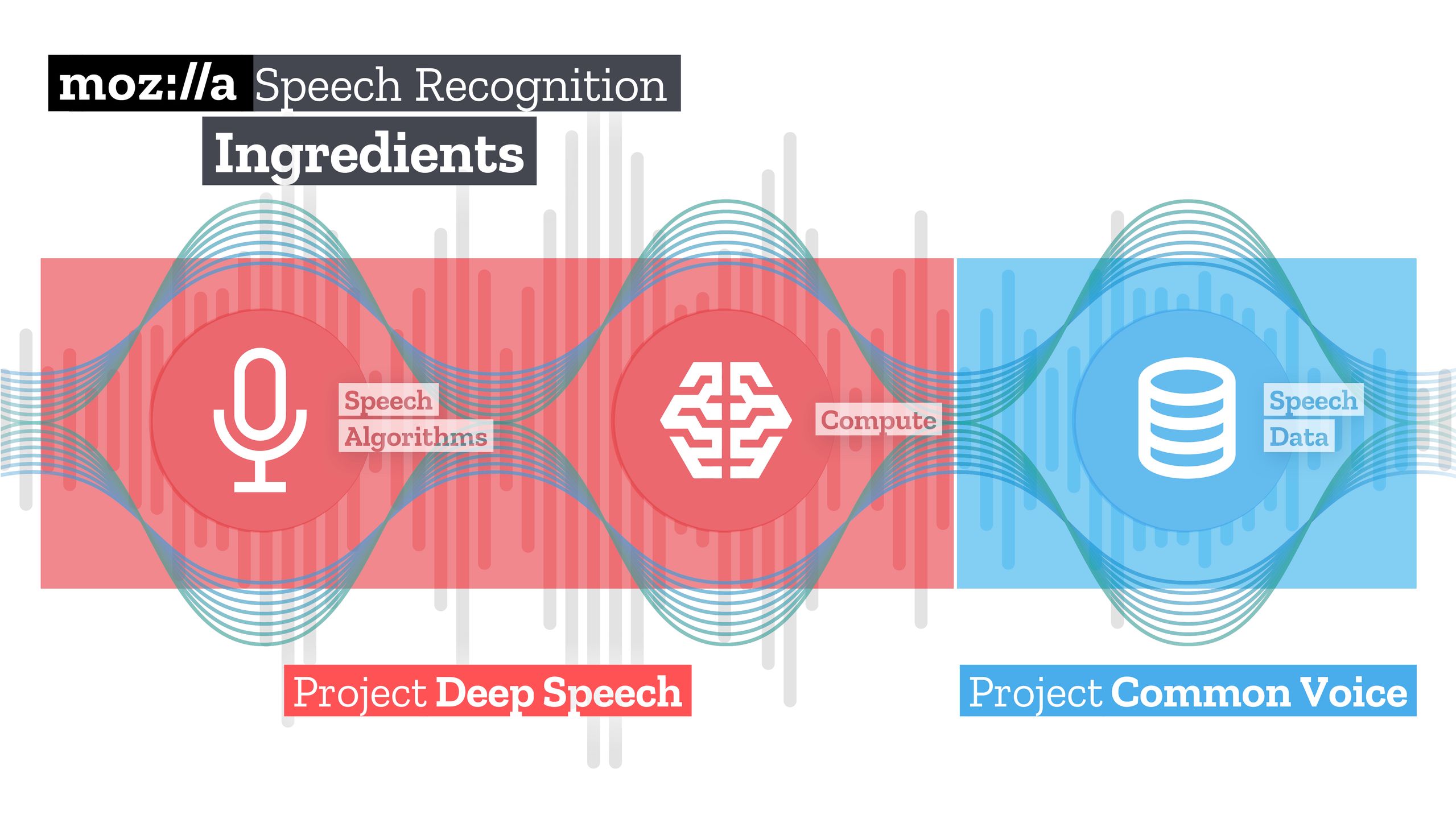
Drugim elementem strategii Mozilli w dziedzinie rozpoznawania mowyjest silnik transkrypcyjny Deep Speech. Inspirowany jest on pracaminaukowców z Baidu iwykorzystuje mechanizmy maszynowego uczenia oferowane przez GoogleTensor Flow, aby jak to określono, ułatwić implementację.Tak czy inaczej mamy do czynienia z opensource’ową, głębokąrekurencyjną siecią neuronową, która może być trenowana znadzorem od podstaw, bez żadnych dodatkowych „źródełinteligencji” – wyjaśnia Rueben Morais, jeden z twórców DeepSpeech.
Wytrenowana sieć neuronowa osiąga znakomite wyniki. Na zbiorzetestowym LibriSpeech uzyskała odsetek błędów na poziomie 6,5%,znacznie lepiej niż zakładano – celowano w osiągnięcie odsetkabłędów na poziomie nie przekraczającym 10%. Zainteresowanychszczegółami architektury zapraszamy na blogaMozilli, tu tylko powiemy, że trening i zbudowanie dobregomodelu mowy dla silnika, który ma około 120 milionów parametrówzajęło około tygodnia, przy wykorzystaniu klastra dwóch serwerówz ośmioma kartami Nvidia Titan XP każdy.
Silnik Deep Speech z takim modelem znaleźć można naGitHubie, dostępne są zarówno prekompilowane binarki jaki ikod źródłowy, klient w Pythonie i powiązania dla node.js i Rusta.Jak na pierwsze wydanie, wydajność jest bardzo dobra: MacBook Prowykorzystujący akcelerację GPU jest w stanie przeprowadzićtranskrypcję 1 sekundy mowy w 0,3 sekundy, bez akceleracji GPUzajmie to około 1,4 sekundy. Docelowo Deep Speech ma zostać takzoptymalizowany, by zapewnić transkrypcję mowy w czasierzeczywistym nawet na urządzeniach mobilnych czy jednopłytkowychkomputerkach.