


VIA odkurza licencję na x86 i powraca z nowym procesorem. Potrafi "stłuc" topowe intele
Nie, dzisiaj nie jest 1 kwietnia, a ty, czytelniku drogi, wcale nie trafiłeś do kapsuły czasu. VIA, po trwającej ponad dekadę stagnacji, powraca na rynek procesorów x86 z zupełnie nową mikroarchitekturą. Nie będzie jednak w bezpośredni sposób rywalizować z Intelem i AMD. Buduje bowiem klasę czipów do tej pory nieznaną.


Układ Centaur CHA, bo o nim tu mowa, jest przedstawiany jako SoC. Niemniej jednak, stosując nomenklaturę producentów głównego strumienia, bliżej mu do konstrukcji po prostu heterogenicznej. Dlaczego? Bo nie ma zintegrowanej grafiki. Ale poza tym detalem faktycznie odpowiada definicji. Ma osiem rdzeni x86, czterokanałowy kontroler pamięci DDR4-3200, kontroler PCI Express z 44 liniami, mostek południowy i niesprecyzowane I/O.
Przy czym jest jeszcze coś: wbudowany koprocesor AI, zwany Ncore, który z rdzeniami nadrzędnymi i kontrolerem RAM komunikuje się poprzez specjalnie zaprojektowaną w tym celu magistralę pierścieniową. I oto kwintesencja napomkniętej unikatowości. Celem nowego czipu jest napędzenie akceleratorów sztucznej inteligencji. Można to porównać do systemów Nvidia Jetson, tyle że w makroskali i nie w oparciu o model programowy Arm.

O samych rdzeniach wiadomo niewiele. Prócz tego, że wspierają zestaw rozszerzeń AVX-512, a cały czip pochłania poniżej 195 mm² i jest produkowany w procesie litograficznym klasy 16 nm przez TSMC. Rozmiar więc wypada dość umiarkowanie. Wytwarzany w zbliżonej technologii 14 nm GloFo, również ośmiordzeniowy AMD Ryzen 7 1800X zajmuje około 213 mm², a przecież nie ma żadnego koprocesora i wykorzystuje mniej tranzystorochłonny interkonekt. Wiadomo za to, że magistrala pierścieniowa taktowana jest z częstotliwością 2,5 GHz. Dobre i to.VIA jest rewolucyjna. Na swój sposóbJuż po sposobie przedstawiania danych widać, co dla architektów VIA stanowiło i stanowi klucz. Jasne, że koprocesor Ncore. Ten oferuje parę rozwiązań, które bardziej popularna konkurencja dopiero planuje wprowadzić. Obsługuje typ BFloat16 i rozszerzenie AVX-512 VNNI (wektoryzacja) dla konwolucyjnych sieci neuronowych. Korzysta przy tym z 4096-bajtowej tablicy w charakterze rejestru, mogąc wykonać 4096(!) 8-bitowych operacji stałoprzecinkowych w cyklu zegara. To osiągnięcie porównywalne do 64-rdzeniowego Xeona Phi, który to jednak jest konstrukcją 3,5-krotnie większą pod względem zużycia krzemu.
A przepustowość na wat to nie jedyna zaleta. Lwia część akceleratorów AI, w tym wywołany Xeon Phi, to dość siermiężny sprzęt do przetwarzania masowo równoległego, przez co wymagający oddzielnego procesora centralnego i logiki. Procesor musi taką zabawkę wykarmić danymi. Za każdym razem. Niech nawet akcelerator ma bezpośredni dostęp do pamięci (DMA); Nvidia utrzymuje obecnie, że jeśli adresów źródłowych lub docelowych nie odwzoruje się w pamięci akceleratora, to błędy są nieuniknione. Zawsze na którymś etapie, czy to w formie przestojów czy cykli pochłanianych na zarządzanie pamięcią, pojawia się wąskie gardło.
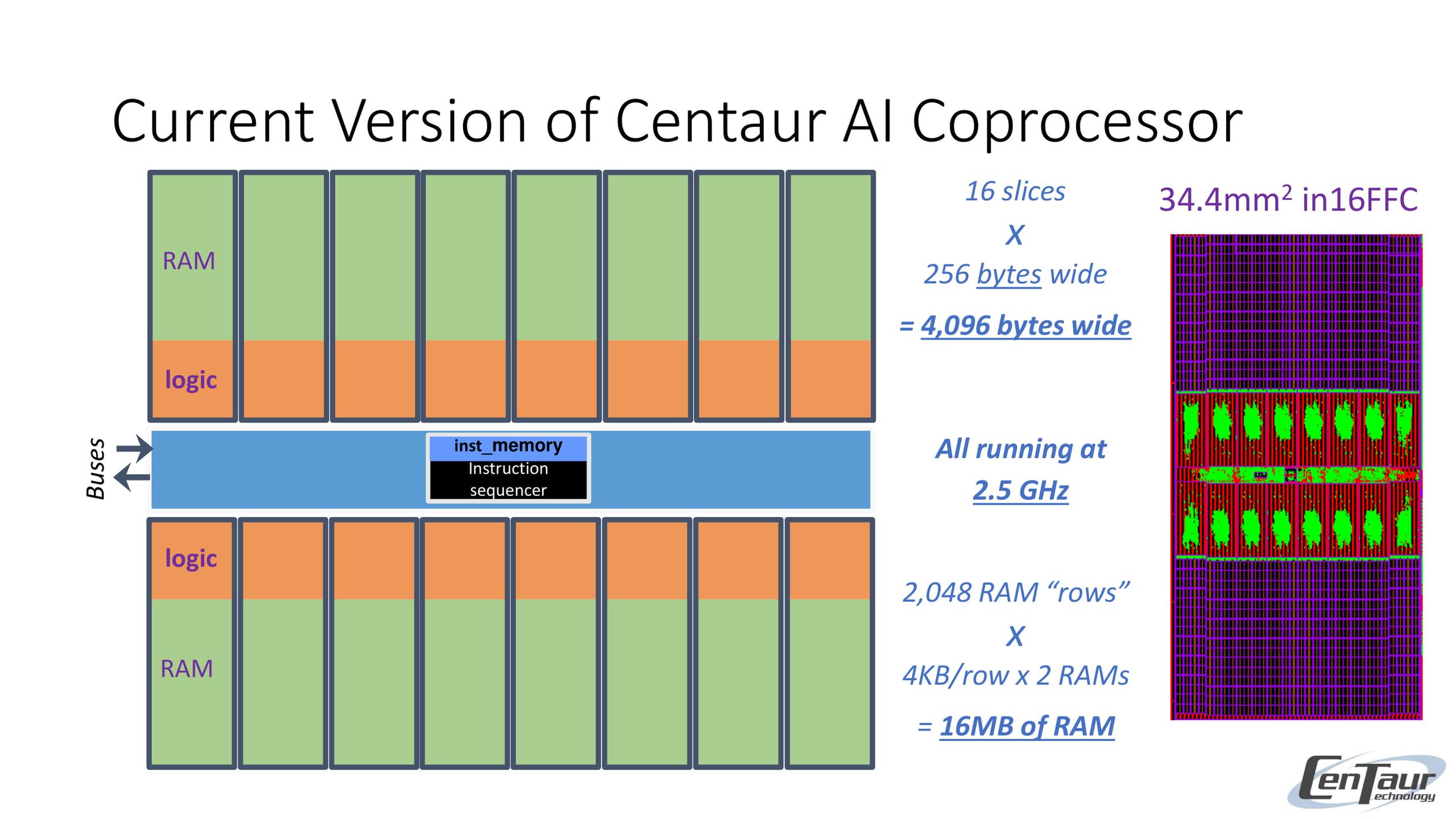
VIA utrzymuje, że Centaur CHA tego problemu nie ma, bo koprocesor operuje aż na 2 MB lokalnej pamięci podręcznej, która może odbierać i przesyłać do części wykonawczej dane z prędkością równą ponoć aż 20 TB/s. Nie mam bladego pojęcia, jak tego dokonano. bo producent szczegółów ujawniać nie chce. Faktem jest, że zazwyczaj takich transferów nie osiągają nawet liczące po parędziesiąt bajtów bloki umieszczane niemalże w centrum rdzenia. Równolegle, dzięki koncepcji magistrali pierścieniowej, Ncore ma dokładnie taki sam czas dostępu do 16 MB L3 i RAM jak rdzenie x86—ale to już i tak oznacza utracone cykle, choć w mniejszym niż zwykle stopniu.
Podsumowując powyższe specyfikacje wyłącznie w oparciu o matematykę, Ncore powinien wykonać 20 bln operacji INT8 w ciągu sekundy, co daje mu wydajność na poziomie 20 TOPS. Rzeczywiście wykonać, a nie zawisnąć na podsystemie pamięci. I zwróćcie uwagę, że cały czas mowa o systemie kompleksowym, o znanym doskonale ISA, który w dodatku – zważywszy na rozmiar rdzenia i technologię produkcji – powinien być bardzo energooszczędny.
Hardware to jedno. A co z oprogramowaniem?
No właśnie, tu zawsze jest największy problem z nowymi układami. Jak twierdzi VIA, zastosowanie modelu programowego x86 jako podstawy spowodowało, że Linuksa, a konkretniej Ubuntu można na Centaurze CHA uruchomić z marszu. Nie ma co z tym dyskutować, bo jądro Linux od dłuższego czasu wspiera chińskie procesory Zhaoxin KX, a te są tworzone pod egidą VIA i zapewne z sekcją x86 wiele rozwiązań współdzielą. Inaczej jest z wykorzystaniem potencjału Ncore.

Nikt nie ukrywa: sprawa jest rozwojowa. VIA sama informuje, że aktualizacje do frameworków wydawane są niemalże z dnia na dzień. Takie PyTorch czy TensorFlow znajdują się dopiero w fazie zapowiedzi. Na slajdzie. Mimo wszystko już teraz widać ogromny potencjał. Niektóre wyniki w bazie MLperf, pomimo zaklasyfikowania do kategorii poglądowej, robią kolosalne wrażenie. Przykład? Test MobileNet-v1 (klasyfikacja obrazu) procesor VIA kończy z blisko 1,5-krotną przewagą nad Xeonem Platinum 9200. Tak, tym 56-rdzeniowym i 400-watowym potworkiem, który kosztuje dobry samochód. Wiadomo, wielowarstwowe sieci neuronowe to scenariusz dość specyficzny, sprzyjający architekturom wektorowym. Ale nikt chyba nie powie, że zabrakło efektu WOW.